Bratin Saha, Xiaocheng Zhou, Sai Luoare, Ying Gao, Shoumeng Yan @ 10:19 EDT | July 22, 2010
The client computing platform is moving towards a heterogeneous architecture that consists of a combination of cores focused on scalar performance, and of a set of throughput-oriented cores
Bratin Saha is a Principal Engineer in Intel Labs. Xiaocheng Zhou and Sai Luoare Research Scientist in Intel Labs, China. Ying Gao and Shoumeng Yan are Reseachers in Intel Labs, China.
Client computing platforms are moving towards a heterogeneous architecture with some processing cores focused on scalar performance and other cores focused on throughput performance. For example, desktop and notebook platforms may ship with one or more CPUs, primarily focused on scalar performance, along with a GPU that can be used for accelerating highly-parallel data kernels. These heterogeneous platforms can be used to provide a significant performance boost on highly-parallel non-graphics workloads in image processing, medical imaging, data mining [6], and other domains [10]. Several vendors have also come out with programming environments for such platforms, such as CUDA [11], CTM [2], and OpenCL [12].
Heterogeneous platforms have a number of unique architectural constraints:
* The throughput-oriented cores (e.g., GPU) may be connected in both integrated and discrete forms. A system may also have a hybrid configuration where a low-power, lower-performance GPU is integrated with the chipset, and a higher-performance GPU is attached as a discrete device. Finally, a platform may also have multiple discrete GPU cards. The platform configuration determines many parameters, such as bandwidth and latency between the different kinds of processors, the cache coherency support, etc.
* The scalar and throughput-oriented cores may have different operating systems. For example, the Larrabee processor [16] can have its own kernel. (Note that in December 2009, Intel announced that the first-generation Larrabee will not be released as a consumer GPU product. More recently, the Technology@Intel blog followed up by announcing that the Larrabee processor would be a product for HPC research (such as that discussed in this article.) The Larrabee processor is a general-throughput computing device that includes a software stack for high-performance graphics rendering. This means that the virtual memory translation schemes (virtual to physical address translation) can be different between the different kinds of cores. The same virtual address can be simultaneously mapped to two different physical addresses -- one residing in CPU memory and the other residing in the Larrabee processor memory. This also means that the system environment (loaders, linkers, etc.) can be different between the two cores. For example, the loader may load the application at different base addresses on different cores.
* The scalar and throughput-oriented cores may have different instruction set architectures (ISAs), and hence the same code cannot be run on both kinds of cores.
A programming model for heterogeneous platforms must address all of the aforementioned architectural constraints. Unfortunately, existing programming models such as Nvidia Compute Unified Device Architecture (CUDA) and ATI Close To the Metal (CTM) address only the ISA heterogeneity, by providing language annotations to mark code that must run on GPUs; they do not take other constraints into account. For example, CUDA does not address the memory management issues between CPU and GPU. It assumes that the CPU and GPU are separate address spaces and that the programmer uses separate memory allocation functions for the CPU and the GPU. Further, the programmer must explicitly serialize data structures, decide on the sharing protocol, and transfer the data back and forth. <./p>
In this article, we propose a new programming model for heterogeneous Intel x86 platforms that addresses all the issues just mentioned. First, we propose a uniform programming model for different platform configurations. Second, we propose using a shared memory model for all the cores in the platform (e.g., between the CPU and the Larrabee cores). Instead of sharing the entire virtual address space, we propose that only a part of the virtual address space be shared to enable an efficient implementation. Finally, like conventional programming models, we use language annotations to demarcate code that must run on the different cores, but we improve upon conventional models by extending our language support to include features such as function pointers.
We break from existing CPU-GPU programming models and propose a shared memory model, since a shared memory model opens up a completely new programming paradigm that improves overall platform performance. A shared memory model allows pointers and data structures to be seamlessly shared between the different cores (e.g., CPU and Larrabee cores) without requiring any marshalling. For example, consider a game engine that includes physics, artificial intelligence (AI), and rendering. A shared memory model allows the physics, AI, and game logic to be run on the scalar cores (e.g., CPU), while the rendering runs on the throughput cores (e.g., Larrabee core), with both the scalar and throughput cores sharing the scene graph. Such an execution model is not possible in current programming environments, since the scene graph would have to be serialized back and forth.
We implemented our full programming environment, including the language and runtime support, and ported a number of highly parallel non-graphics workloads to this environment. In addition, we ported a full gaming application to our system. By using existing models, we spent one and a half weeks coding this application for data management for each new game feature: the game itself included about a dozen features. The serialization arises since the rendering is performed on the Larrabee processor, while the physics and game logic are executed on the CPU. All of this coding (and the associated debugging, etc.) is unnecessary in our system, since the scene graph and associated structures are placed in shared memory and used concurrently by all the cores in the platform. Our implementation works with different operating system kernels running on the scalar and throughput-oriented cores.
We ported our programming environment to a heterogeneous x86 platform simulator that simulates a set of Larrabee, throughput-oriented cores attached as a discrete PCI-Express device to the CPU. We used such a platform for two reasons. First, we believe the Larrabee core is more representative of how GPUs are going to evolve into throughput-oriented cores. Second, the platform poses greater challenges, due to the heterogeneity in the system software stack, as opposed to simply ISA heterogeneity. Later in this article, we present performance results on a variety of workloads.
Larrabee Architecture
The Larrabee architecture is a many-core x86 visual computing architecture that is based on in-order cores that run an extended version of the x86 instruction set, including wide-vector processing instructions and some specialized scalar instructions. Each of the cores contains a 32 KB instruction cache and a 32 KB L1 data cache, and each core accesses its own subset of a coherent L2 cache to provide high-bandwidth L2 cache access. The L2 cache subset is 256 KB, and the subsets are connected by a high-bandwidth, on-die ring interconnect. Data written by a CPU core are stored in their own L2 cache subset and are flushed from other subsets, if necessary. Each ring data path is 512 bits wide in each direction. The fixed function units and memory controller are spread across the ring to reduce congestion.
Each core has four hardware threads with separate register sets for each thread. Instruction issue alternates between the threads and it covers cases where the compiler is unable to schedule code without stalls. The core uses a dual-issue decoder, and the pairing rules for the primary and secondary instruction pipes are deterministic. All instructions can issue on the primary pipe, while the secondary pipe supports a large subset of the scalar x86 instruction set, including loads, stores, simple ALU operations, vector stores, etc. The core supports 64-bit extensions and the full Intel Pentium x86 instruction set. The Larrabee architecture consists of a 16-wide vector processing unit that executes integer, single-precision float, and double-precision float instructions. The vector unit supports gather-scatter and masked instructions, and it supports instructions with up to three source operands.
Memory Model
The memory model for our system provides a window of shared addresses between the CPU and Larrabee cores, such as in PGAS [17] languages, but enhances it with additional ownership annotations. Any data structure that is shared between the CPU and Larrabee core must be allocated by the programmer in this space. The system provides a special malloc function that allocates data in this space. Static variables can be annotated with a type qualifier so that they are allocated in the shared window. However, unlike PGAS languages, there is no notion of affinity in the shared window. This is because data in the shared space must migrate between the CPU and Larrabee caches as they get used by each processor. Also, the representation of pointers does not change between the shared and private spaces.
The remaining virtual address space is private to the CPU and Larrabee processor. By default, data get allocated in this space, and they are not visible to the other side. We choose this partitioned address space approach since it cuts down on the amount of memory that needs to be kept coherent, and it enables a more efficient implementation for discrete devices.
The proposed memory model can be extended in a straightforward way to multiple Larrabee processor configurations. The window of shared virtual addresses extends across all the devices. Any data structures allocated in this shared address window are visible to all agents, and pointers in this space can be freely exchanged between the devices. In addition, every agent has its own private memory as in Figure 1.

Figure 1: CPU-Larrabee processor memory model.
We propose using release consistency in the shared address space for several reasons. First, the system only needs to remember all the writes between successive release points, not the sequence of individual writes. This makes it easier to do bulk transfers at release points (e.g., several pages at a time). This is especially important in the discrete configuration, since it is more efficient to transfer bulk data over PCI-Express. Second, release consistency allows memory updates to be kept completely local until a release point, which is again important in a discrete configuration. In general, the release consistency model is a good match for the programming patterns in CPU-GPU platforms, since there are natural release and acquisition points in such programs. For example, a call from the CPU into the GPU is one such point. Making any of the CPU updates visible to the GPU before the call does not serve any purpose, and neither does it serve any purpose to enforce any order on how the CPU updates become visible, as long as all of them are visible before the GPU starts executing. Finally, the proposed C/C++ memory model [5] can be mapped easily to our shared memory space.
We augment our shared memory model with ownership rights to enable further coherence optimizations. Within the shared virtual address window, the CPU or Larrabee processor can specify at a particular point in time that it owns a specific chunk of addresses. If an address range in the shared window is owned by the CPU, then the CPU knows that the Larrabee processor cannot access those addresses and hence does not need to maintain coherence of those addresses with the Larrabee processor: for example, it can avoid sending any snoops or other coherence information to the Larrabee processor. The same is true of addresses owned by the Larrabee processor. If a CPU-owned address is accessed by the Larrabee processor, then the address becomes un-owned (with symmetrical behavior for those addresses owned by the Larrabee processor). We provide these ownership rights to leverage common usage models. For example, the CPU first accesses some data (e.g., initializing a data structure), and then hands them over to the Larrabee processor (e.g., computing on the data structure in a data parallel manner), and then the CPU analyzes the results of the computation and so on. The ownership rights allow an application to inform the system of this temporal locality and to optimize the coherence implementation. Note that these ownership rights are optimization hints only, and it is legal for the system to ignore these hints.
Language Constructs
To deal with platform heterogeneity, we add constructs to C that allow the programmer to specify whether a particular data item should be shared or private, and to specify whether a particular code chunk should be run on the CPU or on the Larrabee processor.
The first construct is the shared type qualifier, similar to UPC [17], which specifies a variable that is shared between the CPU and Larrabee processor. The qualifier can also be associated with pointer types to imply that the target of the pointer is in shared space. For example, you can write:
shared int var1; // int is in shared space
int var2; // int is not in shared space
shared int* ptr1; // ptr1 points to a shared location
int* ptr2; // ptr2 points to private space
shared int *shared ptr1; // ptr1 points to shared and is shared
The compiler allocates globally shared variables in the shared memory space, while the system provides a special malloc function to allocate data in the shared memory. The actual virtual address range in each space is decided by the system and is transparent to the user.
It is legal for a language implementation to allocate all data in the shared space -- that is, map all malloc calls to the sharedMalloc and allocate all globals in the shared space. A programmer then deals only with shared data. The key point is that our system provides the hooks needed for programmers to demarcate private and shared data, should they want to do that.
We use an attribute, __attribute(Larrabee), to mark functions that should be executed on the Larrabee processor. For such functions, the compiler generates code that is specific to the Larrabee processor. When a non-annotated function calls a Larrabee annotated function, it implies a call from the CPU to the Larrabee processor. The compiler checks that all pointer arguments have shared type and invokes a runtime API for the remote call. Function pointer types are also annotated with the attribute notation, implying that they point to functions that are executed on the Larrabee processor. Non-annotated function pointer types point to functions that execute on the CPU. The compiler checks type equivalence during an assignment; for example, a function pointer with the Larrabee attribute must always be assigned the address of a function that is annotated for the Larrabee processor.
Our third construct denotes functions that execute on the CPU but can be called from the Larrabee processor. These functions are denoted by using __attribute(wrapper). We used this function in two ways.
* First, many programs link with precompiled libraries that can execute on the CPU. The functions in these libraries are marked as wrapper calls so that they execute on the CPU if called from Larrabee code.
* Second, while porting large programs from a CPU-only execution mode to a CPU plus Larrabee processor mode, it is very helpful to incrementally port the program. The wrapper attribute allows the programmer to stop the porting effort at any point in the call tree by calling back into the CPU.
When a Larrabee function calls a wrapper function, the compiler invokes a runtime API for the remote call from the Larrabee processor to the CPU. Making Larrabee-to-CPU calls explicit allows the compiler to check that any pointer arguments have the shared type.
We also provide a construct and the corresponding runtime support for making asynchronous calls from the CPU to the Larrabee processor. This allows the CPU to avoid waiting for Larrabee computation to finish. Instead, the runtime system returns a handle that the CPU can query for completion. Since this does not introduce any new design issues, we focus mostly on synchronous calls in the remainder of this article.
Data Annotation Rules
These rules apply to data that can be allocated in the shared virtual space.
* Shared can be used to qualify the type of variables with global storage. Shared cannot be used to qualify a variable with automatic storage unless it qualifies a pointer's referenced type.
* A pointer in private space can point to any space. A pointer in shared space can only point to shared space but not to private space.
* A structure or union type can have the shared qualifier which then requires all fields to have the shared qualifier as well.
The following rules are applied to pointer manipulations:
* Binary operator (+,-, ==,...) is only allowed between two pointers pointing to the same space. The system provides API functions that perform dynamic checks. When an integer expression is added to or subtracted from a pointer, the result has the same type as the pointer.
* Assignment/casting from pointer-to-shared to pointer-to-private is allowed. If a type is not annotated, we assume that it denotes a private object. This makes it difficult to pass shared objects to legacy functions, since their signature requires private objects. The cast allows us to avoid copying between private and shared spaces when passing shared data to a legacy function.
* Assignment/casting from pointer-to-private to pointer-to-shared is allowed only through a dynamic_cast. The dynamic_cast checks at runtime that the pointer-to-shared actually points to shared space. If the check fails, an error is thrown and the user has to explicitly copy the data from private space to shared space. This cast allows legacy code to efficiently return values.
Our language can allow casting between the two spaces (with possibly a dynamic check) since our data representation remains the same regardless of whether the data are in shared or private space. Even pointers have the same representation regardless of whether they are pointing to private or shared space. Given any virtual address V in the shared address window, both the CPU and Larrabee processor have their own local physical address corresponding to this virtual address. Pointers on the CPU and Larrabee processor read from this local copy of the address, and the local copies get synced up as required by the memory model.
Code Annotation Rules
These rules apply to the code or function, where they execute.
* A __attribute(Larrabee) function is not allowed to call a non-annotated function. This is to ensure that the compiler knows about all the CPU functions that can be called from the Larrabee processor.
* A __attribute(wrapper) function is not allowed to call into a __attribute(Larrabee) function. This is primarily an implementation restriction in our system.
* Any pointer parameter of a Larrabee- or wrapper-annotated function must point to shared space.
The calling rules for functions also apply to function pointers. For example, a __attribute(Larrabee) function pointer called from a non-annotated function results in a CPU-to-Larrabee processor call. Similarly, un-annotated function pointers cannot be called from Larrabee functions. The runtime also provides APIs for mutexes and barriers to allow the application to perform explicit synchronization. These constructs are always allocated in the shared area.
Acquire and release points follow naturally from the language semantics. For example, a call from the CPU to the Larrabee processor is a release point on the CPU followed by an acquire point on the Larrabee processor. Similarly, a return from the Larrabee processor is a release point on the Larrabee and an acquire point on the CPU. Taking ownership of a mutex and releasing a mutex are acquire and release points, respectively, for the processor doing the mutex operation, while hitting a barrier and getting past a barrier are release and acquire points as well.
Ownership Constructs
We also provide an API that allows the user to allocate chunks of memory (hereafter called "arenas") inside the shared virtual region. The programmer can dynamically set the ownership attributes of an arena. Acquiring ownership of an arena also acts as an acquire operation on the arena, and releasing ownership of an arena acts as the release operation on the arena. The programmer can allocate space within an arena by passing the arena as an argument to a special malloc function. The runtime grows the arena as needed. The runtime API is shown here:
// Owned by the caller or shared
Arena *allocateArena(OwnershipType type);
//Allocate and free within arena
shared void *arenaMalloc ( Arena*, size_t);
void arenaFree( Arena *, shared void *);
// Ownership for arena. If null changes ownership of entire shared area
OwnershipType acquireOwnership(Arena*);
OwnershipType releaseOwnership(Arena*);
//Consistency for arena
void arenaAcquire(Arena *);
void arenaRelease(Arena *);
The programmer can optimize the coherence implementation by using the ownership API. For example, in a gaming application, while the CPU is generating a frame, the Larrabee processor may be rendering the previous frame. To leverage this pattern, the programmer can allocate two arenas, with the CPU acquiring ownership of one arena and generating the frame into that arena, while the Larrabee processor acquires ownership of the other arena and renders the frame in that arena. This prevents coherence messages from being exchanged between the CPU and Larrabee processor while the frames are being processed. When the CPU and Larrabee processor are finished with their current frames, they exchange ownership of their arenas, so that they continue to work without incurring coherence overhead.
Implementation
The compiler generates two binaries -- one for execution on the Larrabee processor and another for CPU execution. We generate two different executables since the two operating systems can have different executable formats. The Larrabee binary contains the code that will execute on the Larrabee processor (annotated with the Larrabee attribute), while the CPU binary contains the CPU functions which include all un-annotated and wrapper-annotated functions. Our runtime library has a CPU and Larrabee component that are linked with the CPU and Larrabee application binaries to create the CPU and Larrabee executables. When the CPU binary starts executing, it calls a runtime function that loads the Larrabee executable. Both the CPU and Larrabee binaries create a daemon thread that is used for the communication.
Implementing Shared Memory between the CPU and Larrabee Processor
Our implementation reuses some ideas from software distributed shared memory [9, 4] schemes, but there are some significant differences as well. Unlike DSMs, our implementation is complicated by the fact that the CPU and Larrabee processor can have different page tables and different virtual-to-physical memory translations. Thus, when we want to sync up the contents of virtual address V between the CPU and Larrabee processor (e.g., at a release point), we may need to sync up the contents of different physical addresses, such as P1 on CPU and P2 on the Larrabee processor. Unfortunately, the CPU does not have access to the Larrabee processor's page tables (hence the CPU has no knowledge of P2), and the Larrabee processor cannot access the CPU's page tables and has no knowledge of P1.
We solve the aforementioned problem by leveraging the PCI aperture in a novel way. During initialization we map a portion of the PCI aperture space into the user space of the application and instantiate it with a task queue, a message queue, and copy buffers. When we need to copy pages, for example, from the CPU to the Larrabee processor, the runtime copies the pages into the PCI aperture copy buffers and tags the buffers with the virtual address and the process identifier. On the Larrabee side, the daemon thread copies the contents of the buffers into its address space by using the virtual address tag. Thus, we perform the copy in a two-step process -- the CPU copies from its address space into a common buffer (PCI aperture) that both the CPU and Larrabee processor can access, while the Larrabee processor picks up the pages from the common buffer into its address space. Copies from the Larrabee processor to the CPU are done in a similar way. Note that since the aperture is pinned memory, the contents of the aperture are not lost if the CPU or Larrabee processor gets the context switched out. This allows the two processors to execute asynchronously, which is critical, since the two processors can have different operating systems and hence the context switches cannot be synchronized. Finally, note that we map the aperture space into the user space of the application, thus enabling user-level communication between the CPU and Larrabee processor. This makes the application stack vastly more efficient than going through the operating system driver stack. To ensure security, the aperture space is partitioned among the CPU processes that want to use Larrabee processor. At present, a maximum of eight processes can use the aperture space.
We exploit one other difference between traditional software DSMs and CPU plus Larrabee processor platforms. Traditional DSMs were designed to scale on medium-to-large clusters. In contrast, CPU plus Larrabee processor systems are very small-scale clusters. We expect that no more than a handful of Larrabee cards and CPU sockets will be used well into the future. Moreover, the PCI aperture provides a convenient shared physical memory space between the different processors. Thus, we are able to centralize many data structures and make the implementation more efficient. For example, we put a directory in the PCI aperture that contains metadata about the pages in the shared address region. The metadata states whether the CPU or Larrabee processor holds the golden copy of a page (home for the page), contains a version number that tracks the number of updates to the page, mutexes that are acquired before updating the page, and other miscellaneous metadata. The directory is indexed by the virtual address of a page. Both the CPU and the Larrabee runtime systems maintain a private structure that contains local access permissions for the pages and the local version numbers of the pages.
When the Larrabee processor performs an acquire operation, the corresponding pages are set to no-access on the Larrabee processor. At a subsequent read operation, the page fault handler on the Larrabee processor copies the page from the home location, if the page has been updated and released since the last Larrabee acquire. The directory and private version numbers are used to determine this. The page is then set to read-only. At a subsequent write operation, the page fault handler creates the backup copy of the page, marks the page as read-write, and increments the local version number of the page. At a release point, we perform a diff with the backup copy of the page and transmit the changes to the home location, while incrementing the directory version number. The CPU operations are symmetrical. Thus, between acquire and release points, the Larrabee processor and CPU operate out of their local memory and communicate with each other only at the explicit synchronization points.
At startup the implementation decides the address range that will be shared between the CPU and Larrabee processor, and it ensures that this address range always remains mapped. This address range can grow dynamically and does not have to be contiguous; although in a 64-bit address space, the runtime system can reserve a continuous chunk upfront.
Implementing Shared Memory Ownership
Every arena has associated metadata that identify the pages that belong to the arena. Suppose the Larrabee processor acquires ownership of an arena, we then make the corresponding pages non-accessible on the CPU. We copy from the home location any arena pages that have been updated and released since the last time the Larrabee processor performed an acquire operation. We set the pages to read-only so that subsequent Larrabee writes will trigger a fault, and the system can record which Larrabee pages are being updated. In the directory, we note that the Larrabee processor is the home node for the arena pages. On a release operation, we simply make the pages accessible again on the other side and update the directory version number of the pages. The CPU ownership operations are symmetrical.
Note the performance advantages of acquiring ownership. At a release point we no longer need to perform diff operations, and we do not need to create a backup copy at a write fault, since we know that the other side is not updating the page. Second, since the user provides specific arenas to be handed over from one side to the other, the implementation can perform a bulk copy of the required pages at an acquire point. This leads to a more efficient copy operation, since the setup cost is incurred only once and gets amortized over a larger copy.
Implementing Remote Calls
A remote call between CPU and Larrabee cores is complicated by the fact that the two processors can have different system environments: for example, they can have different loaders. Larrabee and CPU binary code is also loaded separately and asynchronously. Suppose that the CPU code makes some calls into the Larrabee processor when the CPU binary code is loaded, the Larrabee binary code has still not been loaded and hence the addresses for Larrabee functions are still not known. Therefore, the operating system loader cannot patch up the references to Larrabee functions in the CPU binary code. Similarly, when the Larrabee binary code is being loaded, the Larrabee loader does not know the addresses of any CPU functions being called from Larrabee code and hence cannot patch those addresses.
We implement remote calls by using a combination of compiler and runtime techniques. Our language rules ensure that any function involved in remote calls (Larrabee or wrapper attribute functions) is annotated by the user. When compiling such functions, the compiler adds a call to a runtime API that registers function addresses dynamically. The compiler creates an initialization function for each file that invokes all the different registration calls. When the binary code gets loaded, the initialization function in each file gets called. The shared address space contains a jump table that is populated dynamically by the registration function. The table contains one slot for every annotated function. The format of every slot is
where funcName is a literal string of the function name, and funcAddr is the runtime address of the function.
The translation scheme works as follows:
* If a Larrabee (CPU) function is being called within a Larrabee (CPU) function, the generated code will do the call as is.
* If a Larrabee function is being called within a CPU function, the compiler-generated code will do a remote call to the Larrabee processor:
o The compiler-generated code will look up the jump table with the function name and obtain the function address.
o The generated code will pack the arguments into an argument buffer in shared space. It will then call a dispatch routine on the Larrabee side passing in the function address and the argument buffer address.
There is a similar process for a wrapper function: if a wrapper function is called in a Larrabee code, a remote call is made to the CPU.
For function pointer invocations, the translation scheme works as follows. When a function pointer with Larrabee annotation is assigned, the compiler-generated code will look up the jump table with the function name and assign the function pointer with obtained function address. Although the lookup can be optimized when a Larrabee-annotated function pointer is assigned within Larrabee code, we forsake such optimization to use a single strategy for all function pointer assignments. If a Larrabee function pointer is being called within a Larrabee function, the compiler-generated code will do the call as is. If a Larrabee function pointer is being called within a CPU function, the compiler-generated code will do a remote call to the Larrabee side. The process is similar for a wrapper function pointer: if a wrapper function pointer is called in a Larrabee function, a remote call is made to the CPU side.
The signaling between CPU and Larrabee processor happens with task queues in the PCI aperture space. The daemon threads on both sides poll their respective task queues and when they find an entry in the task queue, they spawn a new thread to invoke the corresponding function. The API for remote invocations is described in this code:
// Synchronous and asynchronous remote calls
RPCHandler callRemote(FunctionType, RPCArgType);
int resultReady(RPCHandler);
Type getResult(RPCHandler);
Finally, the CPU and Larrabee processor cooperate while allocating memory in the shared area. Each processor allocates memory from either side of the shared address window. When one processor consumes half of the space, the two processors repartition the available space.
Experimental Evaluation
We used a heterogeneous platform simulator for measuring the performance of different workloads on our programming environment. This platform simulates a modern out-of-order CPU and a Larrabee system. The CPU simulation uses a memory and architecture configuration similar to that of the Intel Core2 Duo processor. The Larrabee system was simulated as a discrete PCI-Express device with an interconnect latency and bandwidth similar to those of PCI-Express 2.0, and the instruction set was modeled on the Intel Pentium processor. It did not simulate the new Larrabee instructions and parts of the Larrabee memory hierarchy, such as the ring interconnect. The simulator ran a production-quality software stack on the two processors. The CPU ran Windows Vista*, while Larrabee processor ran a lightweight operating-system kernel.
We used a number of well-known parallel non-graphics workloads [6] to measure the performance of our system. These include the Black Scholes financial workload that does option pricing by using the Black Scholes method; the fast fourier transform (FFT) workload that does a radix-2 FFT algorithm used in many domains, such as signal processing; the Equake workload, part of SpecOMP, that performs earthquake modeling, and that is representative of high-performance computer (HPC) applications; and Art, also part of SpecOMP, that performs image recognition. The reported numbers are based on using the standard input sets for each of the applications. All these workloads were rewritten by using our programming constructs and were compiled with our tool chain.

Figure 2: Percent of shared data in memory accesses.
Figure 2 shows the fraction that total memory accesses were to shared data in the aforementioned workloads. The vast majority of the accesses were to private data. Note that read-only data accessed by multiple threads were privatized manually. This manual privatization helped in certain benchmarks like Black Scholes. It is not surprising that most of the accesses are to private data, since the computation threads in the workloads privatize the data that they operate on to get better memory locality. We expect workloads that scale to a large number of cores to behave similarly, since the programmer must be conscious of data locality and avoid false sharing in order to get good performance. The partial virtual address sharing memory model lets us leverage this access pattern by cutting down on the amount of data that need to be kept coherent.
We next show the performance of our system on the set of workloads. We ran the workloads on a simulated system with 1 CPU core and varied the number of Larrabee cores from 6 to 24. The workload computation was split between the CPU and Larrabee cores, with the compute-intensive portions executed on Larrabee cores. For example, all the option pricing in Black Scholes and the earthquake simulation in Equake is offloaded to Larrabee cores. We present the performance improvement relative to a single CPU and Larrabee core. Figure 3 compares the performance of our system, when the application does not use any ownership calls, to the performance when the user optimizes the application further by using ownership calls. The bars labeled "Mine/Yours" represent the performance with ownership calls: (Mine implies pages were owned by CPU and Yours implies pages were owned by the Larrabee processor). The bars labeled "Ours" represent the performance without any ownership calls.

Figure 3: Ownership performance comparison.
As expected, the applications perform better with ownership calls than without. To understand the reason for this, we broke down the overhead of the system when the application was not using any ownership calls. Figure 4 shows the breakdown for Black Scholes. We show the breakdown for only one benchmark, but the ratios of the different overheads are very similar in all the benchmarks.

Figure 4: Overhead breakdown without ownership.
We break up the overhead into four categories.
* The first one relates to handling the page faults, since we use a virtual memory-based shared memory implementation, and reads/writes to a page after an acquire point triggers a fault.
* The second relates to the diff operation performed at release points to sync up the CPU and Larrabee copies of a page.
* The third is the amount of time spent in copying data from one side to the other. The copy operation is triggered from the page fault handler when either processor needs the latest copy of a page. We do not include the copy overhead as part of the page fault overhead, but present it separately, since we believe different optimizations can be applied to optimize it.
* Finally, the fourth one shows the overhead spent in synchronizing messages. Note that in a discrete setting, the Larrabee processor is connected to the CPU over the PCI-Express. The PCI-Express protocol does not include atomic read-modify-write operations. Therefore we have to perform some synchronization and hand shaking between the CPU and Larrabee processor by passing messages.

Figure 5: Overhead breakdown with ownership.
When the application uses ownership of arenas, the diff overhead is completely eliminated. The page fault handling is reduced, since the write page-fault handler does not have to create a backup copy of the page. Moreover, since we copy all the pages in one step when we acquire ownership of an arena, we do not incur read page faults.

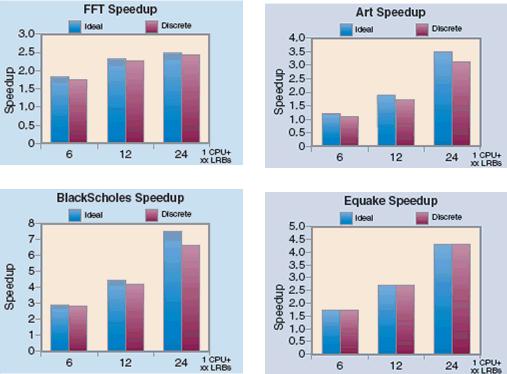
Figure 6: Overall performance comparison.
This also significantly reduces the synchronization message overhead since the CPU and Larrabee processor perform the handshaking at only ownership acquisition points rather than at many intermediate points (e.g., whenever pages are transferred from one side to the other). Figure 5 shows the overhead breakdown with ownership calls.
Finally, Figure 6 shows the overall performance of our system. All the workloads used the ownership APIs. The "ideal" bar represents hardware-supported cache coherence between the CPU and Larrabee cores -- in other words, this is the best performance that our shared memory implementation can provide. For Equake, since the amount of data transferred is very small compared to the computation involved, we notice that "ideal" and "discrete" times are almost identical.
In all cases our shared memory implementation has low overhead and performs almost as well as the ideal case. Black Scholes shows the highest comparable overhead, since it has the lowest compute density: i.e., the amount of data transferred per unit computation time was the highest. Using Black Scholes we transfer about 13MB of data per second of computation time, while we transfer about 0.42MB of data per second of computation time when using Equake. Hence, the memory coherence overhead is negligible in Equake. The difference between the ideal scenario and our shared memory implementation increases with the number of cores, mainly due to synchronization overhead. In our implementation, synchronization penalties increase non-linearly with the number of cores.
Related Work
There exists other research that is closely related to the work explicated in this article. Most closely related are the CUDA [11], OpenCL [12] and CTM [2] programming environments. Just as our technology does, OpenCL uses a weakly consistent shared memory model, but it is restricted to the GPU. Our work differs from CUDA, OpenCL, and CTM in several ways: unlike these environments we define a model for communication between the CPU and Larrabee processor; we provide direct user-level communication between the CPU and Larrabee processor, and we consider a bigger set of C language features, such as function pointers. Implementing a similar memory model is challenging on current GPUs due to their inherent limitations.
The Cell processor [8] is another heterogeneous platform. While the power processor unit (PPU) is akin to a CPU, the synergistic processing units (SPUs) are much simpler than the Larrabee cores. For example, they do not run an operating system kernel. Unlike the SPU-PPU pair, the Larrabee processor and CPU pair is much more loosely coupled, since the Larrabee processor can be paired as a discrete GPU with any CPU running any operating system. Unlike our model, Cell programming involves explicit direct memory access (DMA) between the PPU and SPU. Our memory model is similar to that of PGAS languages [14, 17], and hence our language constructs are similar to those of Unified Parallel C (UPC) language [17]. However, UPC does not consider ISA or operating system heterogeneity. Higher-level PGAS languages such as X10 [14] do not support the ownership mechanism that is crucial for a scalable, coherent implementation in a discrete scenario. Our implementation has similarities to software-distributed shared memory [9, 4] which also leverages virtual memory. Many of these S-DSM systems also use release consistency and they copy pages lazily on demand. The main differences with S-DSM systems is the level of heterogeneity. Unlike S-DSM systems, our system needs to consider a computing system where the processors have different ISAs and system environments. In particular, we need to support different processors with different virtual-to-physical page mappings. Finally, the performance tradeoffs between S-DSMs and CPU with Larrabee processor systems are different: S-DSMs were meant to scale on large clusters, while CPU with Larrabee processor systems should remain small scale clusters for some time in the future. The CUBA [7] architecture proposes hardware support for faster communication between the CPU and GPU. However, the programming model assumes that the CPU and GPU are separate address spaces. The EXO [18] model provides shared memory between a CPU and accelerators, but it requires the page tables to be kept in sync, which isn't feasible in a discrete accelerator.
Conclusions
Heterogeneous computing platforms composed of a general-purpose scalar oriented CPU and throughput-oriented cores (e.g., a GPU) are increasingly being used in client computing systems. These platforms can be used for accelerating highly parallel workloads. There have been several programming model proposals for such platforms, but none of them address the CPU-GPU memory model. In this article we propose a new programming model for a heterogeneous Intel x86 system with the following key features:
* A shared memory model for all the cores in the platform.
* A uniform programming model for different configurations.
* User annotations to demarcate code for CPU and Larrabee execution.
We implemented the full software stack for our programming model including compiler and runtime support. We ported a number of parallel workloads to our programming model and evaluated the performance on a heterogeneous Intel x86 platform simulator. We show that our model can be implemented efficiently so that programmers are able to benefit from shared memory programming without paying a performance penalty.
References
[1] Adve S, Adve V, Hill M.D. and Vernon M.K. "Comparison of Hardware and Software Cache Coherence Schemes." International Symposium on Computer Architecture (ISCA), 1991.
[2] AMD CTM Guide. "Technical Reference Manual." 2006 Version 1.01. Available at http://www.amd.com
[3] AMD Stream SDK. Available at ati.amd.com/technology/streamcomputing.
[4] Amza C., Cox A.L., Dwarkadas S., Keleher P., Lu H., Rajamony R., Yu W., Zwaenepoel W. "TreadMarks: Shared Memory Computing on Networks of Workstations." IEEE Computer, 29(2): pages 18-28, February 1996.
[5] Boehm H., Adve S. "Foundations of the C++ memory model." Programming Language Design and Implementation (PLDI), 2008.
[6] Dubey P. "Recognition, Mining, and Synthesis moves computers to the era of tera." Available at Technology@Intel, February 2005.
[7] Gelado I., Kelm J.H., Ryoo S., Navarro N., Lumetta S.S., Hwu W.W. "CUBA: An Architecture for Efficient CPU/Co-processor Data Communication." ICS, June 2008.
[8] Gschwind M., Hofstee H.P., Flachs B., Hopkins M., Watanabe Y., Yamakazi T. "Synergistic Processing in Cell's Multicore Architecture." IEEE Micro, April 2006.
[9] Kontothanasis L., Stets R., Hunt G., Rencuzogullari U., Altekar G., Dwarkadas S., Scott M.L. "Shared Memory Computing on Clusters with Symmetric Multiprocessors and System Area Networks." ACM Transactions on Computer Systems, August 2005.
[10] Luebke, D., Harris, M., Krüger, J., Purcell, T., Govindaraju, N., Buck, I., Woolley, C., and Lefohn, A. "GPGPU: general purpose computation on graphics hardware." SIGGRAPH, 2004.
[11] Nvidia Corporation. "CUDA Programming Environment." Available at www.nvidia.com/
[12] OpenCL 1.0. Available at http://www.khronos.org/opencl/
[13] Ryoo S., Rodrigues C.I., Baghsorki S.S., Stone S.S., Kirk D.B., Hwu W.W. "Optimization Principles and Application Performance Evaluation of a Multithreaded Larrabee using CUDA." Principles and Practice of Parallel Programming (PPoPP), 2008.
[14] Saraswat, V. A., Sarkar, V., and von Praun, C. "X10: concurrent programming for modern architectures." PpoPP, 2007.
[15] Saha, B., Adl-Tabatabai, A., Ghuloum, A., Rajagopalan, M., Hudson, R. L., Petersen, L., Menon, V., Murphy, B., Shpeisman, T., Sprangle, E., Rohillah, A., Carmean, D., and Fang, J. "Enabling scalability and performance in a large scale CMP environment." Eurosys, 2007.
[16] Seiler L., Carmean D., Sprangle E., Forsyth T., Abrash M., Dubey P., Junkins S., Lake A., Sugerman J., Cavin R., Espasa R., Grochowski E., Juan T., Hanrahan P. "Larrabee: A Many-Core x86 Architecture for Visual Computing." ACM Transactions on Graphics, August 2008.
[17] "UPC Consortium, UPC language specifications." Lawrence Berkeley National Lab Tech Report LBNL-59208, 2005.
[18] Wang P., Collins J.D., Chinya G. N., Jiang H., Tian X., Girkar M., Yang N. Y., Lueh G., Wang H. "Exochi: Architecture and programming environment for a heterogeneous multi-core multithreaded system." Programming Language Design and Implementation (PLDI), 2007.
Acknowledgments
We thank the following people who provided us with much support in this work: Jesse Fang, Ian Lewis, Antony Arciuolo, Kevin Myers, Robert Geva, Ravi Narayanaswamy, Milind Girkar, Rajiv Deodhar, Stephen Junkins, David Putzolu, Allen Hux, Peinan Zhang, Patrick Xi, Dean Macri, Nikhil Rao, Rob Kyanko, Madan Venugopal, Srinivas Chennupaty, Stephen Van Doren, Allen Baum, Martin Dixon, Ronny Ronen, Stephen Hunt, Larry Seiler, and Mike Upton.
This article and more on similar subjects may be found in the Intel Technology Journal, December 2009 Edition, "Addressing the Challenges of Tera-scale Computing". More information can be found at http://intel.com/technology/itj.
Sphere: Related Content










+18.20.50.png)




