

Keep in mind that the CPU privilege level has nothing to do with operating system users. Whether you’re root, Administrator, guest, or a regular user, it does not matter. All user code runs in ring 3 and all kernel code runs in ring 0, regardless of the OS user on whose behalf the code operates. Sometimes certain kernel tasks can be pushed to user mode, for example user-mode device drivers in Windows Vista, but these are just special processes doing a job for the kernel and can usually be killed without major consequences.
Due to restricted access to memory and I/O ports, user mode can do almost nothing to the outside world without calling on the kernel. It can’t open files, send network packets, print to the screen, or allocate memory. User processes run in a severely limited sandbox set up by the gods of ring zero. That’s why it’s impossible, by design, for a process to leak memory beyond its existence or leave open files after it exits. All of the data structures that control such things – memory, open files, etc – cannot be touched directly by user code; once a process finishes, the sandbox is torn down by the kernel. That’s why our servers can have 600 days of uptime – as long as the hardware and the kernel don’t crap out, stuff can run for ever. This is also why Windows 95 / 98 crashed so much: it’s not because “M$ sucks” but because important data structures were left accessible to user mode for compatibility reasons. It was probably a good trade-off at the time, albeit at high cost.
The CPU protects memory at two crucial points: when a segment selector is loaded and when a page of memory is accessed with a linear address. Protection thus mirrors memory address translation where both segmentation and paging are involved. When a data segment selector is being loaded, the check below takes place:
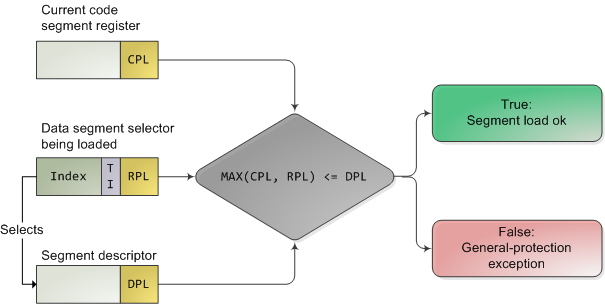
In truth, segment protection scarcely matters because modern kernels use a flat address space where the user-mode segments can reach the entire linear address space. Useful memory protection is done in the paging unit when a linear address is converted into a physical address. Each memory page is a block of bytes described by a page table entry containing two fields related to protection: a supervisor flag and a read/write flag. The supervisor flag is the primary x86 memory protection mechanism used by kernels. When it is on, the page cannot be accessed from ring 3. While the read/write flag isn’t as important for enforcing privilege, it’s still useful. When a process is loaded, pages storing binary images (code) are marked as read only, thereby catching some pointer errors if a program attempts to write to these pages. This flag is also used to implement copy on write when a process is forked in Unix. Upon forking, the parent’s pages are marked read only and shared with the forked child. If either process attempts to write to the page, the processor triggers a fault and the kernel knows to duplicate the page and mark it read/write for the writing process.
Finally, we need a way for the CPU to switch between privilege levels. If ring 3 code could transfer control to arbitrary spots in the kernel, it would be easy to subvert the operating system by jumping into the wrong (right?) places. A controlled transfer is necessary. This is accomplished via gate descriptors and via the sysenter instruction. A gate descriptor is a segment descriptor of type system, and comes in four sub-types: call-gate descriptor, interrupt-gate descriptor, trap-gate descriptor, and task-gate descriptor. Call gates provide a kernel entry point that can be used with ordinary call and jmp instructions, but they aren’t used much so I’ll ignore them. Task gates aren’t so hot either (in Linux, they are only used in double faults, which are caused by either kernel or hardware problems).
That leaves two juicier ones: interrupt and trap gates, which are used to handle hardware interrupts (e.g., keyboard, timer, disks) and exceptions (e.g., page faults, divide by zero). I’ll refer to both as an “interrupt”. These gate descriptors are stored in the Interrupt Descriptor Table (IDT). Each interrupt is assigned a number between 0 and 255 called a vector, which the processor uses as an index into the IDT when figuring out which gate descriptor to use when handling the interrupt. Interrupt and trap gates are nearly identical. Their format is shown below along with the privilege checks enforced when an interrupt happens. I filled in some values for the Linux kernel to make things concrete.

During initialization, the Linux kernel first sets up an IDT in setup_idt() that ignores all interrupts. It then uses functions in include/asm-x86/desc.h to flesh out common IDT entries in arch/x86/kernel/traps_32.c. In Linux, a gate descriptor with “system” in its name is accessible from user mode and its set function uses a DPL of 3. A “system gate” is an Intel trap gate accessible to user mode. Otherwise, the terminology matches up. Hardware interrupt gates are not set here however, but instead in the appropriate drivers.
Three gates are accessible to user mode: vectors 3 and 4 are used for debugging and checking for numeric overflows, respectively. Then a system gate is set up for the SYSCALL_VECTOR, which is 0×80 for the x86 architecture. This was the mechanism for a process to transfer control to the kernel, to make a system call, and back in the day I applied for an “int 0×80″ vanity license plate. Starting with the Pentium Pro, the sysenter instruction was introduced as a faster way to make system calls. It relies on special-purpose CPU registers that store the code segment, entry point, and other tidbits for the kernel system call handler. When sysenter is executed the CPU does no privilege checking, going immediately into CPL 0 and loading new values into the registers for code and stack (cs, eip, ss, and esp). Only ring zero can load the sysenter setup registers, which is done in enable_sep_cpu().
Finally, when it’s time to return to ring 3, the kernel issues an iret or sysexit instruction to return from interrupts and system calls, respectively, thus leaving ring 0 and resuming execution of user code with a CPL of 3. Vim tells me I’m approaching 1,900 words, so I/O port protection is for another day. This concludes our tour of x86 rings and protection. Thanks for reading!
Comments
59 Responses to “CPU Rings, Privilege, and Protection”
1.Amjith on August 20th, 2008 2:58 pm
Wow! Amazing articles Gustavo. I have a question regarding the Memory Translation article. You had mentioned that modern x86 kernels use the “flat model” without any segmentation. But won’t that restrict the size of the addressable memory to ~4GB? But I’ve seen computers with more than 4GB installed, how does that work? Or is it a restriction per program rather than the total memory?
2.Gustavo Duarte on August 21st, 2008 4:51 am
Thanks!
The segments only affect the translation of “logical” addresses into “linear” addresses. Flat model means that these addresses coincide, so we can basically ignore segmentation. But all of the linear addresses are still fed to the paging unit (assuming paging is turned on), so there’s more magic that happens there to transform a linear address into a physical address.
Check the first diagram of the previous post, it should make it more clear. Flat model eliminates the first step (logical to linear), but the last step remains and enables addressing of more than 4GB.
Now, regarding maximum memory, there are three issues: the size of the linear address space, the conversion of a linear address into a physical address, and the physical address pins in the processor so it can talk to the bus.
When the CPU is in 32-bit mode, the linear address space is _always_ 32-bits and is therefore limited to 4 GB. However, the physical pins coming out of CPU can address up to 64GB of RAM on the bus since the Pentium Pro.
So the trouble is all in the translation of linear addresses into physical addresses. When the CPU is running in “traditional” mode, the page tables that transform a linear address into a physical one only work with 32-bit physical addresses, so the computer is confined to 4 GB total RAM.
But then Intel introduced the Physical Address Extension (PAE) to enable servers to use more physical memory. This changes the MECHANISM of translation of a linear address into a physical address. It works by changing the format of the page tables, allowing more bits for the physical address. So at that point, more than 4 GB of physical memory CAN be used.
The problem is that processes are still confined to a 32-bit linear address space. So if you have a database server that wants to address 12 gigs, say, it will have to map different regions of physical memory at a time. It only has a 4 gig linear window into the 12 gigs of physical ram.
Did that make sense?
3.Alex Railean on August 21st, 2008 8:01 am
Hi, this is a nice article, thank you. I also read the other stuff I found on this site and I really like your writing style (very user friendly, you could be a teacher) and the topics you cover. I’ve subscribed to the RSS feed and am looking forward to your new articles.
I’m really impressed.
I have a question – which tool do you use to draw those awesome diagrams? (I hope not Visio)
4.Gustavo Duarte on August 21st, 2008 11:54 am
@Alex: thanks!
Unfortunately, it is Visio 2007. I haven’t tried the open office counterpart. If anyone knows of a FOSS alternative that can produce good diagrams, I’d love to hear about it. I’d like to publish some of this stuff as diagrams for people to reuse (especially network packets), so it’d be cool to have an open platform.
5.Joey on August 21st, 2008 11:59 am
I always thought each user process in Linux had its OWN segment and 4 gigs of virtual address space. I kind of see now that each process does not have its own segment, but if that is true how does the kernel let each process have its own 4 gigs worth of virtual space?
6.Gustavo Duarte on August 21st, 2008 12:27 pm
Having the same segment only affects the translation of logical addresses into linear addresses – and flat mode makes them the same. Most CPUs don’t even have a distinction between “logical” and “linear” – they only deal with linear and physical addresses. It’s an accident of history that x86 ended up with this logical/linear distinction, and x86-64 basically gets rid of it.
But each process still has a different set of _page tables_ mapping its 32-bit linear address space into physical addresses. So the way you thought is actually accurate, it’s just the terminology that was fuzzy. Processes have their own _page tables_, not segment.
7.Amjith on August 22nd, 2008 8:59 am
Hey Gustavo, thanks for taking the time to clarify my question. Now that brings up another sub-question. If we want to use the PAE, we need changes in the kernel code, right? Is that why we have server versions of Windows? A little bit of googling provides insight into how Linux handles this. I believe they enable PAE by default these days, is my understanding correct?
8.Gustavo Duarte on August 22nd, 2008 6:47 pm
@Amjith: that’s right, the kernel needs to do most of the work, since it’s the one responsible for building the page tables for the processes.
Also, if a single process wants to use more than 4GB, then the process _also_ must be aware of this stuff, because it needs to make system calls into the kernel saying “hey, I want to map physical range 5GB to 6GB in my 2GB-3GB linear range”, or “map 10GB-11GB now”, and so on. (Of course, there would be security checks. Also, these are some nice round numbers, usually it’d probably be done in chunks of X KB of memory, depends on the application).
Regarding Windows, that’s an interesting point. It’s too strong to say that PAE _is_ why we have server versions of Windows, but it’s definitely something Microsoft has used extensively for price discrimination. Not only on the Windows kernel, but also apps like SQL Server have pricier editions that support PAE. The kernel for the server editions of Windows has other tweaks as well though, in the algorithms for process scheduling and also memory allocation. But PAE has definitely been one carrot (or stick?) to get some more money.
Linux has had PAE support since the start of 2.6. To use it one must enable it at kernel compile time. I’m not sure if it’s enabled in the kernels that ship with the various distros. I’ve never looked much into the kernel PAE code to be honest, so I’m ignorant here. My understanding though is that if it’s enabled, it’s once and for all in the machine, for all CPUs and processes.
9.technichristian.net » Blog Archive » CPU Rings, Privilege, and Protection on August 25th, 2008 9:35 pm
[...] being protected: memory, I/O ports, and the ability to execute certain machine instructions. At any given time, an x86 CPU is running in a specific privilege level, which determines what code c…. Write a [...]
10.Manav on August 25th, 2008 11:02 pm
Nice article. Just wondering, which software do you use to create the images?
11.Gustavo Duarte on August 25th, 2008 11:03 pm
@Manav: thanks. I use MS Visio 2007.
12.kernel_daemon on August 26th, 2008 12:22 am
I really like your articles. Keep on writing
13.amjith on August 26th, 2008 12:55 am
Hey Gustavo,
Since you asked for an alternative for Visio you can give Dia a shot. “Dia is roughly inspired by the commercial Windows program ‘Visio’, though more geared towards informal diagrams for casual use.” That is a quote from their website.
14.Aditya Nag on August 26th, 2008 7:50 am
Great article. Though I understood very little , I can appreciate that the subject has been lucidly explained. Do keep on writing, I for one am going to be dropping by often.
15.Gokdeniz Karadag on August 26th, 2008 9:05 am
Great series of articles.
I learned lots of intricate parts of the x86 arch that I did not learn at school.
Keep up the good work!
16.D'oh on August 27th, 2008 1:56 pm
What happened to ring 1 and 2?
17.Gustavo Duarte on August 28th, 2008 1:07 am
Thank you all for the feedback
@Aditya: is there a specific part where it “trails off” and stops making sense? Anything I can do, any definitions to introduce, that might clear it up? I’m really interested in learning how to improve my writing to make it more understandable, so I appreciate feedback on this.
@D’oh: I’ll quote from an excellent comment on osnews by siride:
Because other platforms only had two modes, so OSes intended to be used cross-platform preferred to use only two of the four rings. Also, some parts of the IA-32 architecture don’t distinguish 4 rings, but only two modes: system and user, where system means rings 0, 1 and 2, and user means ring 3. Page protection is like this, for example. And finally, adding extra rings just adds extra complexity that could probably be dealt with by using more comprehensive security methodologies, which is currently the case. In much the same way that it’s better to avoid using x86 segmentation or TSS’s for task switching in favor of a software solution that is portable and can be fine-tuned to the needs of the OS in general, or even at a particular point in time (such as under heavy load, etc.).
18.Raminder on August 28th, 2008 6:05 am
Great article as always Gustavo, keep up the good work. You’ve helped clear so many cobwebs in my head. Thanks!
19.Everything you got to know about CPU rings, Privilege and Protection in Intel x86 processors | l . i . n . k . e . r on August 29th, 2008 9:55 pm
[...] here Share this: These icons link to social bookmarking sites where readers can share and discover new [...]
20.Marcelo Gomez on August 30th, 2008 10:21 am
Great article Gustavo! Like the others. Could you mention good resources and bibliography? Keep on writing:)
21.Gustavo Duarte on August 31st, 2008 11:39 pm
Thank you all for the feedback.
@Marcelo: Check out the suggestions at the end of my posts about motherboard chipsets and also the kernel boot process, they link to a few good resources. I really like the Intel documents and those kernel books.
Also, if you are particularly interested in low-level security, the book Subverting the Windows Kernel is a great read, focused on Windows.
22.Ken on September 9th, 2008 9:36 am
Nice Article,
I found this researching the extensions Intel made to support virtualization. If you have any insight into that I think it would make a great article.
23.lallous on September 15th, 2008 9:53 am
Hello Gustavo,
How can one transfer from Ring 0 to Ring 3 ? Or more generalized from a more privileged to a less privileged mode?
Thanks,
lallous
24.Anand Thakur on September 27th, 2008 3:23 am
Hi Gustavo Duarte,
All your articles are extremely great:). I am enjoying your articles.
I am asking a question which is come from your a reply to a question with title “Amjith on August 22nd, 2008 8:59 am”. In that reply you mentioned, to use PAE we need some changes in the kernel code.
Please please correct me if I am wrong.
My thinking like below:
Whenever we want to use PAE, we need to write code,in kernel:
1. which will enable PAE bit in control register
2. Security check at kernel code level
And whenever any application want to map physical range, let say, 5GB to 6GB in 2GB-3GB linear range then this requirement will be handle by hardware itself(Note: This is contradiction with your reply). Kernel dont have to handle this.
To handle above requirement hardware will do like below:
1. First check for PAE is enable or not
2. if PAE is not enable then trap will happen
3. If PAE is enable then complete the reqirement.
All above info from me is my intuitive feeling.
I am requesting u please correct me if I am wrong.
Thanks
25.Anand on September 28th, 2008 2:00 am
Hi Gustavo Duarte,
All your articles are extremely great:). I am enjoying your articles.
I am asking a question which is come from your a reply to a question with title “Amjith on August 22nd, 2008 8:59 am”. In that reply you mentioned, to use PAE we need some changes in the kernel code.
Please please correct me if I am wrong.
My thinking like below:
Whenever we want to use PAE, we need to write code,in kernel:
1. which will enable PAE bit in control register
2. Security check at kernel code level
And whenever any application want to map physical range, let say, 5GB to 6GB in 2GB-3GB linear range then this requirement will be handle by hardware itself(Note: This is contradiction with your reply). Kernel dont have to handle this.
To handle above requirement hardware will do like below:
1. First check for PAE is enable or not
2. if PAE is not enable then trap will happen
3. If PAE is enable then complete the reqirement.
All above info from me is my intuitive feeling.
I am requesting u please correct me if I am wrong.
Thanks
26.baozhao on October 12th, 2008 6:28 am
“First, its contents cannot be set directly by load instructions such as mov, “, probably it’s wrong.The following is excerpted from INTEL 80386 PROGRAMMER’S REFERENCE MANUAL ,1986.
3.10 Segment Register Instructions
This category actually includes several distinct types of instructions.
These various types are grouped together here because, if systems designers
choose an unsegmented model of memory organization, none of these
instructions is used by applications programmers. The instructions that deal
with segment registers are:
1. Segment-register transfer instructions.
MOV SegReg, …
MOV …, SegReg
PUSH SegReg
POP SegReg
2. Control transfers to another executable segment.
JMP far ; direct and indirect
CALL far
RET far
3. Data pointer instructions.
LDS
LES
LFS
LGS
LSS
27.baozhao on October 12th, 2008 9:21 am
sorry,you’re right. It’s my fault
28.Anand on October 19th, 2008 2:47 am
Hi baozhao ,
Sorry, I did not get you.You r replying to my answer?
If yes, Please please write clear reply(because i dont know much about x86 assembly programming)…
Thanks for your reply…..Please reply to my answer asp.
Thank You
Anand
29.Justin Blanton | CPU rings, privilege, and protection on November 2nd, 2008 10:13 pm
[...] CPU rings, privilege, and protection. © 1999-2008 Justin Blanton (email) e v e r y t h i n g i s r e l a t i v e In partnership with [...]
30.Robert on November 4th, 2008 4:44 am
Hi Gustavo,
“When sysenter is executed the CPU does no privilege checking, going immediately into CPL 0″
I was wondering what exactly happens when SYSENTER is called. The code control will be transferred to SegSelector:Offset pointed by vector 0×80 in the IDT is it? Usually what does that code do….?
How will the usermode application then differentiate the various calls made to the kernel mode, eg: a call to get a file; to access a port etc.
How will the return values from the kernel be passed back to the usermode process then?
Thanks and great article btw… Appreciate if you could furnish more details
31.Timur Izhbulatov on November 15th, 2008 2:46 pm
Thanks for the article Gustavo! It’s really helpful.
But there’s still a question I can’t answer. Why do people often talk about “a process in kernel/user mode”, while this is actually the CPU that gets switched from one mode to another?
Thanks,
Timur
32.Bruno on November 17th, 2008 8:59 am
@lallous: Did you read the blog entry before replying?
“Finally, when it’s time to return to ring 3, the kernel issues an iret or sysexit instruction to return from interrupts and system calls (…)”
@Anand: If you use PAE, the kernel _must_ be fully aware, because the kernel must tell the CPU that virtual address x is physical address y, this done in the page tables.
Without PAE the page table as the following format:
– 32bits page address entry
– 2 levels deep
With PAE the page table as the following format:
– 64bits page address entry
– 3 levels deep
There’s another thing to be aware, the virtual address space is split in two halfs, the lower half is the per process address space and the upper half is the kernel address space. Effectivly user mode only has 2GB (or 8EB in 64bits) address space. Now you should see the importance of 64bits, the kernel 2GB space is getting _very_ small (does who say that 32bits is enouth for desktops pc’s are ignoring the kernel).
@Robert: The sysenter (on x86-32) instructions jumps to the address specified in the IA32_SYSENTER_EIP machine specific register. You pass the syscall number on the eax register (linux and nt) and get the return code in eax, arguments are passed (by value or by reference) in registers and the stack (you also have to pass in a register a pointer to the user stack since it will be swaped to the kernel stack on sysenter), once the sysenter jumps to the kernel handler, arguments passed on the user stack are copied to the kernel stack and jump to the function in the system call (sys_xxx on linux, NtXxx on nt) table using the index provided by the user mode (after being validated of course).
33.Berny G on December 1st, 2008 2:15 pm
Gustavo, I greatly enjoy reading your articles. Thank you.
BTW: Enjoyed the pertinent pic of Ken and Dennis and their/your inference to Ring 0.
Keep the articles coming
34.Tej parkash on December 5th, 2008 2:44 am
Nice Article.
It would have been nice if you give some example e.g vi test.c and ./test
35.Gustavo Duarte on December 5th, 2008 10:17 am
Thanks for the feedback.
@Berny: You’re the first to comment on the pic haha, it was my favorite part of the post
@Tej: that’s an interesting idea. What would you show though? Some stepping through C code in a user mode-to-kernel transition? Or the assembly as you transition into the kernel?
36.Gustavo Duarte on December 5th, 2008 10:26 am
@Timur:
Sorry for the delay.
that’s a great question. I actually hope to write a post exactly about these transitions between user mode and kernel mode.
You’re absolutely correct that it is the CPU that changes between modes (ring 0 and ring 3).
But we say ‘process’ because it is the process on whose behalf the CPU is running. So for example, you are running your text editor. It is in user mode (ring 3) say, while it is doing some formatting on the text for you. Then you tell it to SAVE the file. Since the text editor needs to rely on the kernel to do that, it makes a _system call_ (“hey kernel, write THIS stuff to that file”).
As part of that system call, there is a transition to kernel mode and ring 0. The code that actually performs the trasition is part of the C library that underlies the system call (glibc in Linux, and DLLs in Windows).
But now the KERNEL starts to execute, in ring 0. But it is ON BEHALF of your text editor process, so we say that your process is now in kernel mode.
Does that make sense?
37.Timur Izhbulatov on December 5th, 2008 11:57 am
@Gustavo: Thank you so much for your reply!
Indeed this is a very interesting question. I hope to see your new article about processes!
I would like to share some of my thoughts. Please correct me if I’m wrong.
I think we need to further clarify what a process is. As I understand, a process is a running program. That is, a binary image (instructions and data) loaded by the kernel into main memory for execution. OTOH, there are internal data structures that represent running processes in the kernel and a whole subsystem to manage them.
So, from user’s point of view, a system call looks like a function call, but which is translated into a sequence of CPU instructions that set registers and issue an interrupt. Everything beyond this point is hidden from user, but essentially the control is passed over to the kernel interrupt handler. That is, the CPU starts executing some other instructions which are not part of the initially loaded image…
This leads me to the point that my initial statement was not completely correct. Seems that it only explains how a process is viewed from the user space. Which is actually… well… an illusion created by the kernel…
Apparently, there is some level of indirection. The kernel routine executing on behalf of my process does NOT belong to the later. I assume that while the routine is advancing on the CPU, the process itself is “waiting” (its state is saved be the kernel) until the system call returns. I can imagine a situation when there are several processes waiting for some I/O to finish but can we say they are all in kernel mode while another process’ instructions are being executed by the CPU?..
Looks like I gotta get a copy Understanding Linux Kernel or a similar book
Again, thanks for such a fascinating article and discussion!
38.Gustavo Duarte on December 6th, 2008 3:31 am
@Timur:
Basically everything you have said is correct. I’ll only try to clarify some of the points you expressed doubts about.
First, regarding memory. This _definitely_ needs a post, but I’ll do a quick explanation for now. Let’s assume the processor is running in 32-bit mode to keep everything easy.
Each process has 4 gigabytes of memory that it can access (because the processor is using 32 bits to address memory). The kernel sets up a virtual memory space for the process to run in.
Here’s one catch: the first 3 gigabytes actually contain the PROCESS (its executable code, stack, allocated memory, etc). The final gigabyte belongs to the KERNEL and is full of kernel code and data. So after the interrupt (or SYSENTER instruction) the kernel code mapped in this fourth (and last) gigabyte starts running. Meanwhile, the lower 3 gigabytes still contain the process that jumped into kernel mode.
Another interesting thing: 4th gigabyte is COMMON across all processes. So the kernel is always ‘resident’ so to speak, but the mapping of the 3 lower gigabytes keeps changing with changing processes.
Regarding your example of several processes waiting for some I/O. Yes, it IS correct to say that they are all in kernel mode. They are also _sleeping_ though, waiting for that I/O. When the I/O completes, the kernel will scan a data structure that stores the processes that are sleeping on it. It will then wake up each process that was sleeping in kernel mode.
When the process wakes up, it’ll resume execution in kernel mode, exactly where it went to sleep. Then the I/O completes, the kernel returns, and the process is back in user mode.
There’s quite a lot of material here, but I hope the comment helps out some. I hope to cover some of these topics in upcoming posts. Also, your understanding is pretty much all correct as far as I know, it sounds like there are just some details you don’t know about, but your idea of the whole thing seems accurate to me.
39.Gustavo Duarte on December 6th, 2008 4:09 am
the process itself is “waiting” (its state is saved be the kernel) until the system call returns.
Regarding the state being saved, this is all accomplished via the stack. Processes have two stacks: a user mode stack and a kernel mode stack. The stacks are used to preserve state when the process goes from user mode to kernel mode, and also when a process goes to sleep in kernel mode.
40.Timur Izhbulatov on December 6th, 2008 7:41 am
Gustavo, thanks for the explanations! I look forward to your new posts. This is just great that while having such deep understanding of system internals you put so much effort into sharing it with the world in accessible form.
Maybe someday, once you have enough articles, you’ll put them together and publish as a book?
41.Andrew Kirsanow on December 11th, 2008 2:33 pm
It’s nice to clear up some of this stuff, so thank you Sir. Would you happen to know if there is any test code out there to verify/demonstrate legal and illegal control transfers? I have been writing an X86 emulator as a hobby project for about 5 years now (started 5 years ago and took 4 and a half years off) and now I’ve come back to it I’m finding that some of the apps which fail to run are protected mode apps which die in suspect ways that I can only assume are due to errors in the control transfer opcode handling code. I would love a way to test the validity of this code without having to write yet another longwinded ASM test harness!
42.Gustavo Duarte on December 12th, 2008 12:58 am
@Andrew: you’re welcome, my pleasure.
Sounds like a cool project, but I don’t know of such code off the top of my head. Two projects though that may have stuff like that though are Valgrind and the project for the user-mode kernel. They may have things that could help you out.
43.Andrew Kirsanow on December 15th, 2008 6:02 am
Thanks man! I will have a look into those projects. Yes, the project is cool to me because I made the primary design goal to use nobody else’s code either core or BIOS etc. In that way, I suppose it’s 3 projects in one as I develop VGA, BIOS and emulator core. I can currently run a lot of 386 DOS extender apps and Windows 3 runs in standard mode but there are still some apps that just fail for no apparent reason. Hence the thinking that I may have missed something in the PM privilege testing code, maybe some apps rely on the GP exceptions intentionally to allow the extenders to perform some task or other, a bit like marking pages Read only to signal the time to produce physical copies of process pages in fork.
44.el_bot on December 28th, 2008 2:45 pm
Regarding PAE in Windows: XP supports PAE using the “PAE switch” in boot.ini (but anyway it’s restricted to 4GB !!! http://www.microsoft.com/whdc/system/platform/server/PAE/PAEdrv.mspx ok, with PAE you get support of DEP by hardware… why? I don’t know). It’s should be noted that Windows and Linux support PAE in different ways: boot option vs compilation option (correct me if I am wrong).
Regarding “process in kernel/user mode”: I think that terminology is wrong (at least, confusing): a process never runs in kernel mode (i.e, ring 0); in ring 0 only runs the kernel. In every instant the CPU can be in one the following states:
- running a user process (ring 3, your code)
- running a syscall (ring 0, kernel code)
- running a interrupt handler (ring 0, kernel code)
- runnign a kernel thread (ring 0, kernel code)
The phrase “the process is in kernel mode” is, anyway, common (albeit incorrect… at least for the “purists” ).
Saludos
45.Gustavo Duarte on December 29th, 2008 1:05 am
@el_bot:
Regarding the PAE, Windows actually has a different binary for the PAE-enabled kernel. It is \Windows\System32\Ntkrnlpa.exe. So it is a compile-time option as well, but you are correct that we can pass a boot time option to select the PAE kernel.
Regarding the kernel modes, I think you are correct in all that you wrote:
A process’ code does NOT run in kernel mode, ever;
The states you describe are all correct.
But it’s a terminology issue. The case of the running syscall is what people usually think of when saying “the process is running in kernel mode”. Because the process has a kernel-mode stack that is directly tied to it, I think it’s a fair way to call it. At any rate, people use the term widely, so it became a de facto term for the syscall case.
46.el_bot on December 30th, 2008 7:54 am
Yes, you are right: there is two kernels (maybe more) in Windows. And yes: “the process is running in kernel mode” == “kernel is runing a syscall in behalf of the user process”.
Recgarding the kernel-mode stack, I have this hypothesis:
“Actually, there is only one kernel-mode stack (by CPU o core). It’s is shared by syscalls (therefore, by all processes), interrupts handlers, and kernel threads running in this CPU. It’s have a page size (4KB or 8KB). The excellent quality of the kenel code make it size sufficient (i.e, is unlikely a stack overflow)”
I’m not completely sure about this, except that interrupt handlers really use the same kernel stack that would be used by kernel if the current user process would issued a syscall. Well, maybe I’m wrong in this late point.
I’m waiting your article about memory layout (layout logical and/or layout physical) of a running linux kernel (with process, handlers, syscalls, etc). And, of course, with your beautiful illustrations!
Saludos
47.Anatomy of a Program in Memory : Gustavo Duarte on January 27th, 2009 12:34 am
[...] space is flagged in the page tables as exclusive to privileged code (ring 2 or lower), hence a page fault is triggered if user-mode programs try to touch it. In Linux, [...]
48.Mark Lambert on January 31st, 2009 11:52 pm
Brilliant article. Gustavo, you are a hero for taking the time to put these articles together. Your style is absolutely wonderful.
49.Gustavo Duarte on February 1st, 2009 1:17 am
@Mark: thanks so much for the feedback! *blush*
I enjoy writing the posts though, so I can’t claim self sacrifice. : P It’s fun, I learn a ton myself, and it’s great to feel like I’m helping people out a little by making decent content.
Regards to all you folks at MS.
50.Ya-tou & me » Blog Archive » Anatomy of a Program in Memory on February 19th, 2009 1:44 am
[...] map whatever physical memory it wishes. Kernel space is flagged in the page tables as exclusive to privileged code (ring 2 or lower), hence a page fault is triggered if user-mode programs try to touch it. In Linux, [...]
51.内存剖析 « Rock2012’s Blog on May 3rd, 2009 4:22 am
[...] map whatever physical memory it wishes. Kernel space is flagged in the page tables as exclusive to privileged code (ring 2 or lower), hence a page fault is triggered if user-mode programs try to touch it. In Linux, [...]
52.Funktionsweise eines Betriebssystems | duetsch.info - GNU/Linux, Open Source, Softwareentwicklung, Methodik und Vim. on December 28th, 2009 6:20 am
[...] CPU Rings, Privilege, and Protection [...]
53.Jose on January 7th, 2010 2:31 pm
Very nice writtings Mr David ,
I have a question.
When Bios is postboot and the next the kernel beging starting
the kernel use only the memory represented by bios ???
54.nebor on May 24th, 2010 10:06 pm
Fantastic article gustavo!!!
But one thing started confusing me. It’s related to sysexit. After this instruction, CPU sets CS to hardcoded value ( code selector which points to segment descriptor with base 0, limit 4GB, and privilege level 3).
How does it work after this?
linear address is now different, because new CS is in use (logic address is added to NEW code segment base address to create linear).
55.Tuan on May 28th, 2010 9:48 pm
I just know this website by chance, and it’s really helpful.
56.Inside Program Memory « h e a d – w o r d on June 6th, 2010 12:32 am
[...] map whatever physical memory it wishes. Kernel space is flagged in the page tables as exclusive to privileged code (ring 2 or lower), hence a page fault is triggered if user-mode programs try to touch it. In Linux, [...]
57.Johnson on June 21st, 2010 7:45 am
i was just pass-by
58.Faraz on November 10th, 2010 3:08 am
Thanks, Gustavo
this article is very helpful for me.
Thanks again Sphere: Related Content






+18.20.50.png)



 Blinklist.com
Blinklist.com


No hay comentarios:
Publicar un comentario